
Next-Gen AV and The Challenge of Optimizing Big Data at Scale
At SentinelOne, we provide full visibility into managed endpoint data for our customers. Over time, the amount of data events we need to store, search and retrieve has become huge, and we currently handle around 200 billion events per day. While collection and storage is easy enough, querying the data quickly and efficiently is the main challenge. In this post, we will share how we overcame this challenge and achieved the ability to quickly query tremendous amounts of data.

Architectural Overview
Our event stream results in a lot of small files, which are written to S3 and HDFS. We store our partitions in Hive Metastore and query it with Presto. Files are partitioned by date where every day a new partition is automatically created.
We started in a naive way, by simply aggregating events in the pipeline into files being periodically pushed to S3. While this worked well at the beginning, as scale surged, a serious problem emerged.
To allow near real-time search across our managed endpoints, we wrote many small files, rather than attempting to combine them into larger files. We also support the arrival of late events, so data might arrive with an old timestamp after a few days.
Unfortunately, Presto doesn’t work well with many small files. We were working with tens of thousands of files, from hundreds of kilobytes to tens of megabytes. Leaving data in many small files, obviously, made queries very slow, so we faced the challenge of solving the common problem of “small files”.
Attempt 1 — Reduce Frequency of Writing
Our first thought was simply to write less often. While this reduced the number of files, it conflicted with our business constraints of having events searchable within a few minutes. Data is flushed frequently to allow queries on recent events, thus generating millions of files.
Our files are written in ORC format, so appending ORC files is possible, but not effective. When appending ORC stripes, without decompressing the data and restructuring the stripes, the results are big files that are queried really slowly.
Attempt 2 — In-place Compaction
Next, we tried to compact files on the fly in S3. Since our data volumes were small, we were able to compact the files in-memory with Java code. We maintained Hive Metastore for partition locations. It was quite a simple solution, but it turned out to be a headache.
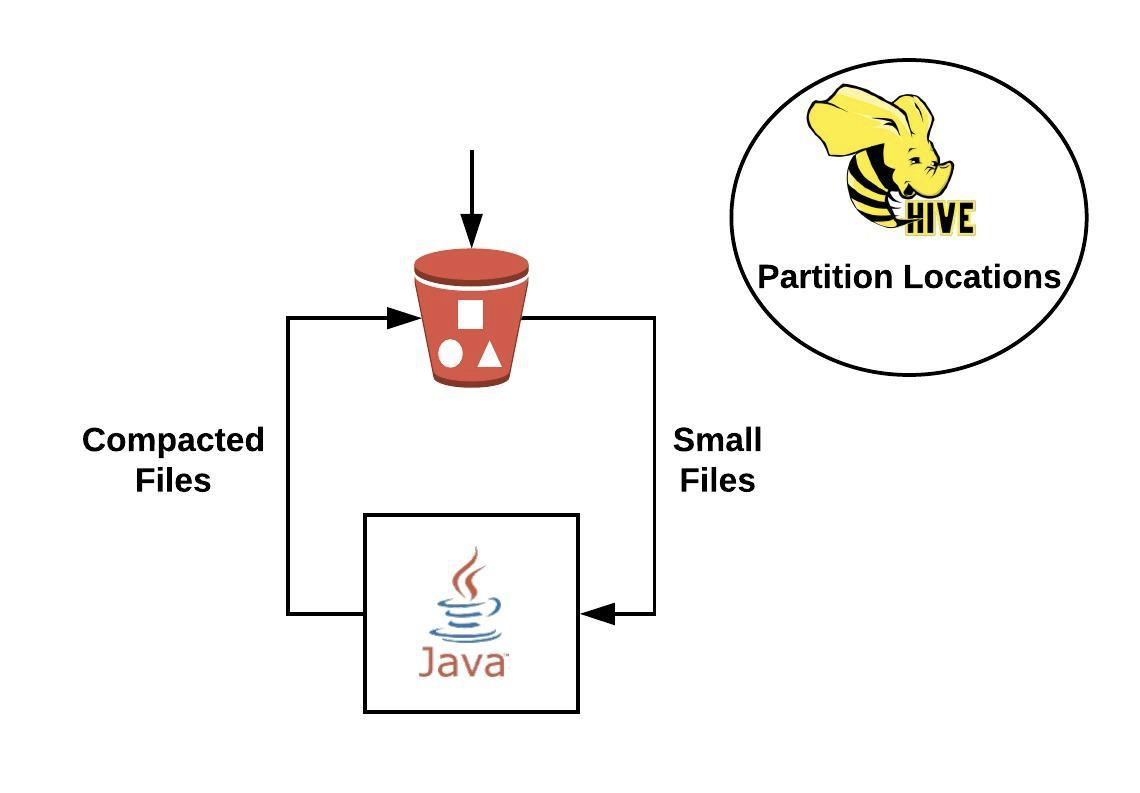
Compacting files in-place is challenging since there’s no way to make atomic writes in S3. We had to take care of deletion of small files that were replaced by compacted files. While the Hive Metastore partitioning was pointing to the same S3 location, we ended up with duplicate or missing data for a while.
S3 listing is eventually consistent:
Although the file would be uploaded successfully, it might appear in the list perhaps half an hour later. Those issues were unacceptable, so we returned to the small files problem.
Attempt 3 — Write files to HDFS, Then Copy to S3
To mitigate S3 eventual consistency, we decided to move to HDFS, which Presto supports natively and as such the transition required zero work.
The small files problem is a known issue in HDFS. HDFS name node holds all file system metadata in memory. Each entry takes about 1 KB. As the amount of files grows, HDFS requires a lot of RAM.
We experienced even worse degradation when trying to save our real time small files in S3:
- When querying the data in presto, it retrieves the partition mapping from the Hive metastore, and lists the files in each partition. As mentioned above, S3 listing is eventually consistent, so in real-time we sometimes missed a few files in the list response. Listing in HDFS is deterministic and immediately returns all files.
- S3 list API response is limited to 1000 entries. When listing a directory of large amounts of files, Hive executes several API requests, which cost time.
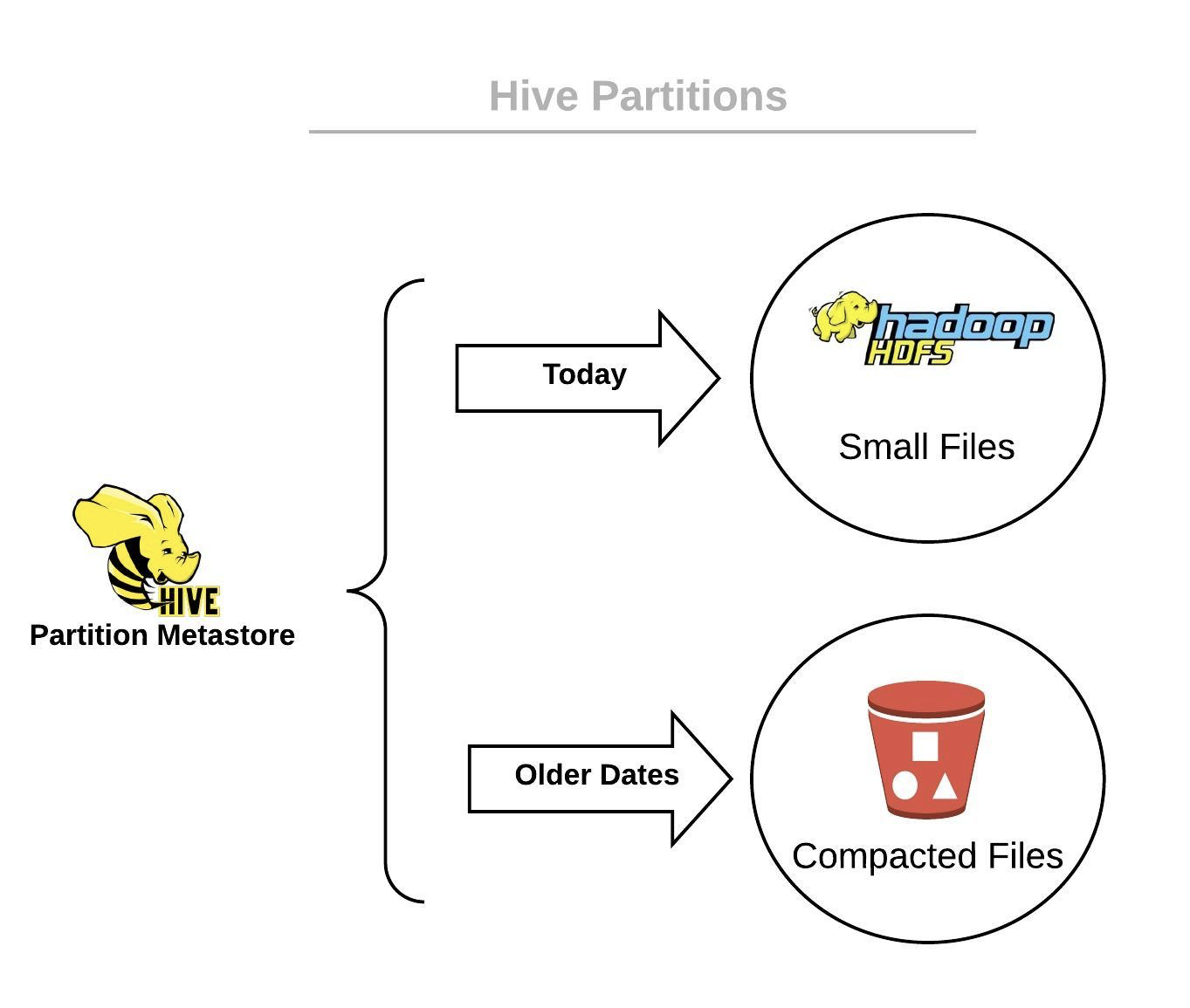
We stored files in Hive Metastore, different locations for each partition, where Today pointed to HDFS and the files of older data pointed to S3.
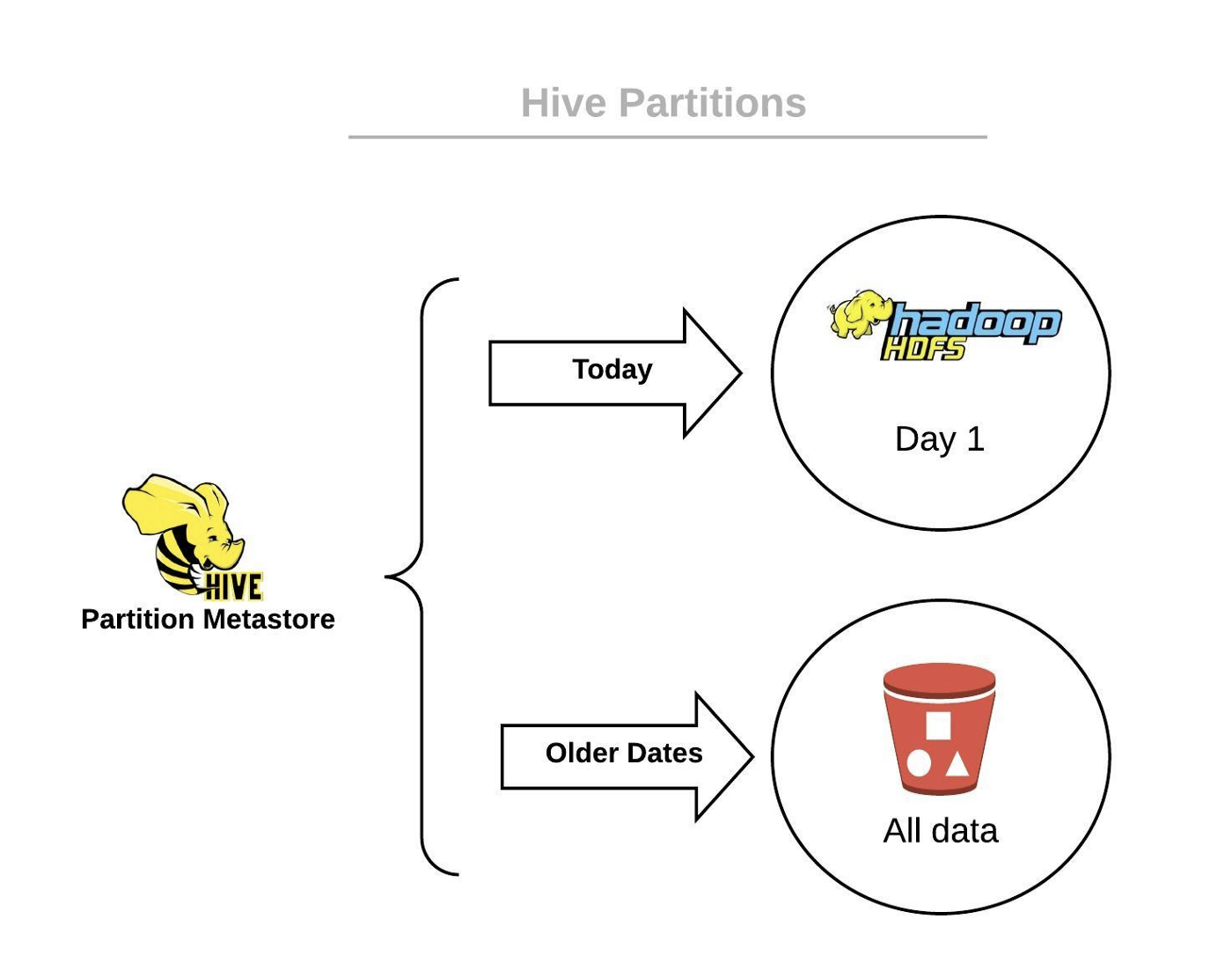
This solution solved our consistency issues, but still, small files are problematic! How can we avoid that? Let’s try compaction again.
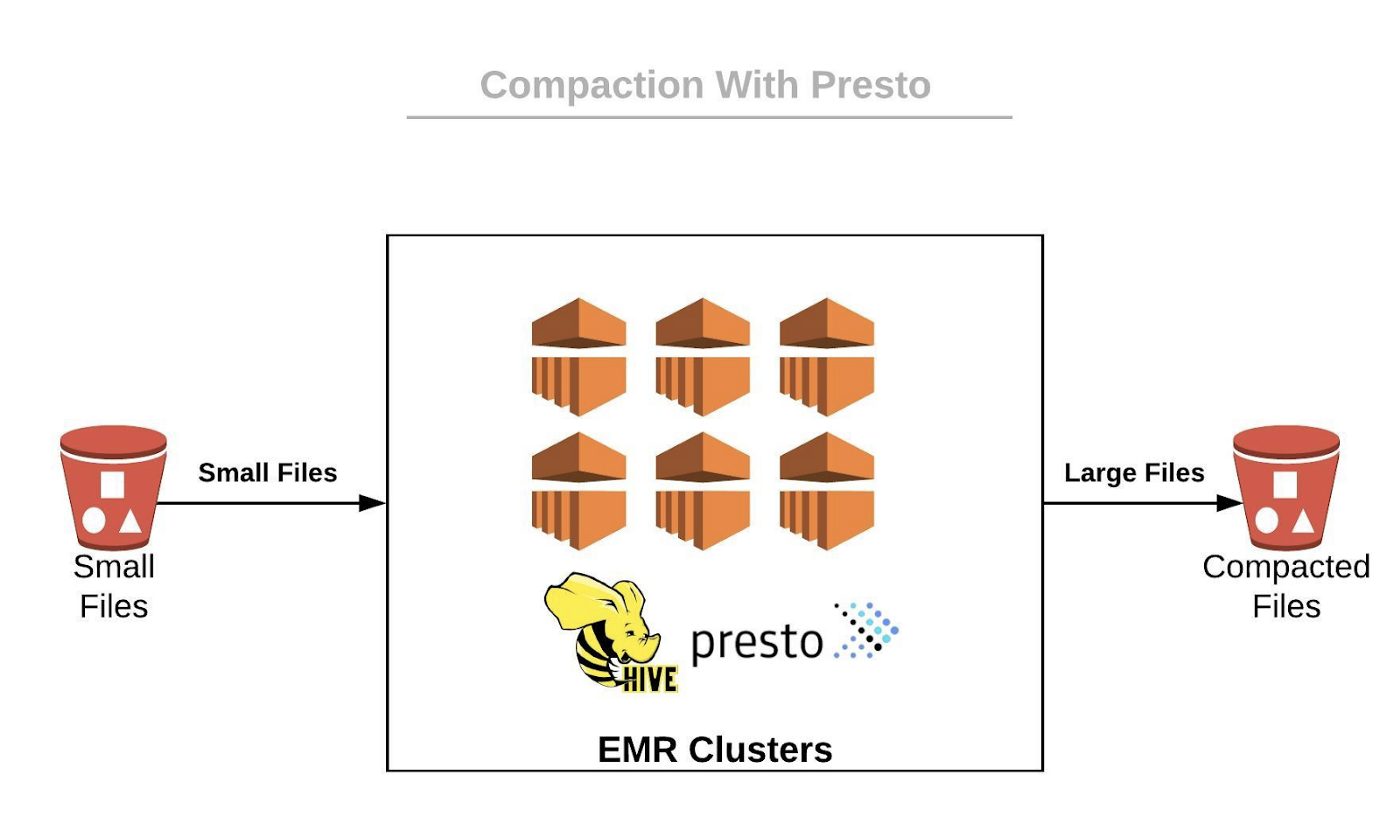
Attempt 4 — Compaction with Presto Clusters
To spawn a Presto cluster and run compaction with it is simple and easy.
At the end of each day, we created EMR clusters that handled compaction on the last day files. Our clusters had hundreds of nodes, memory-optimized with the compaction done in-memory.
When you set up a Presto cluster, you need to do these steps:
- Set these parameters to optimize compacted files output:
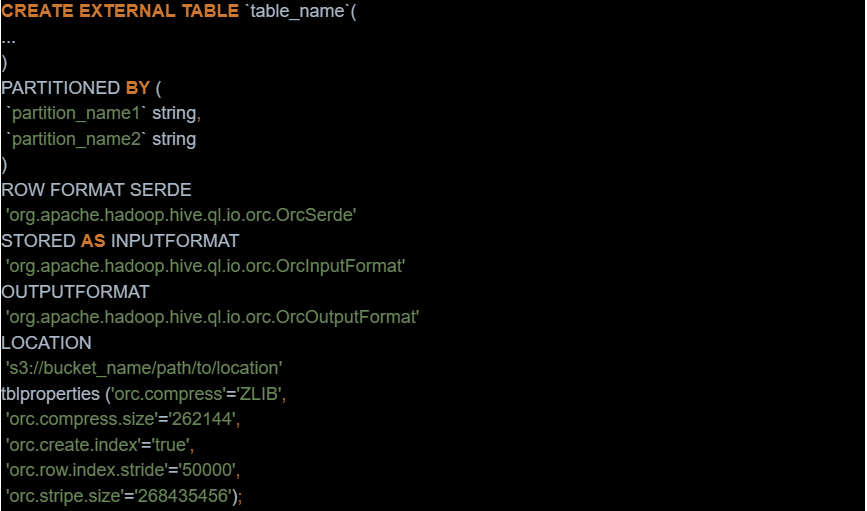
- Create two external tables — a source table with raw data and a destination table of compacted data — based on this template:
- Add partitions to the Hive store, for the source and destination tables to point to the correct location:
- Finally, run the insert magical command, that will do the compaction:

![]()
![]()
The rapid growth in SentinelOne’s data made this system infeasible from a cost and maintenance perspective. We encountered several problems as our data grew:
- Each big partition had 200 GB on disk, which in memory is in fact 2T of raw, uncompressed data every day. Compaction is done on uncompressed data, so holding it in memory through the entire process of compaction required huge clusters.
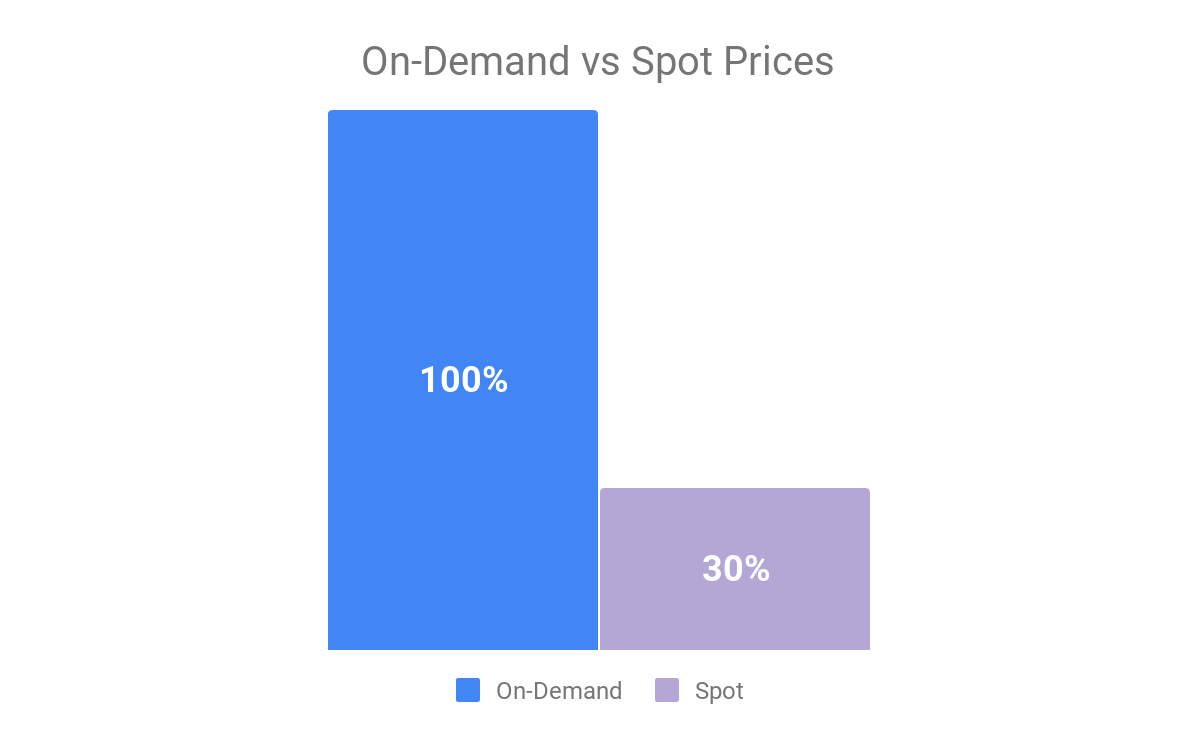
- Running a few clusters with hundreds of nodes is quite expensive. First, we ran with Spots to reduce costs, but as our cluster grew, it became hard to get a lot of big nodes for several hours. At peak, one cluster ran for 3 hours to get one big partition compacted. When we moved to On-Demand machines, costs increased dramatically.
- Presto has no built-in fault-tolerance mechanism, which is very disruptive when running on Spots. If even one Spot failed, the whole operation failed, and we had to run it all over again. This caused delays in switching to compacted data, which resulted in slower queries.
As we started to compact files, Hive Metastore locations were changed to point to compacted data vs. current-day, small-file data.
At the end of the compaction process, we had a job that switched Hive Metastore partitioning.
Attempt 5 — Compact the Files Take 2: Custom-Made Compaction
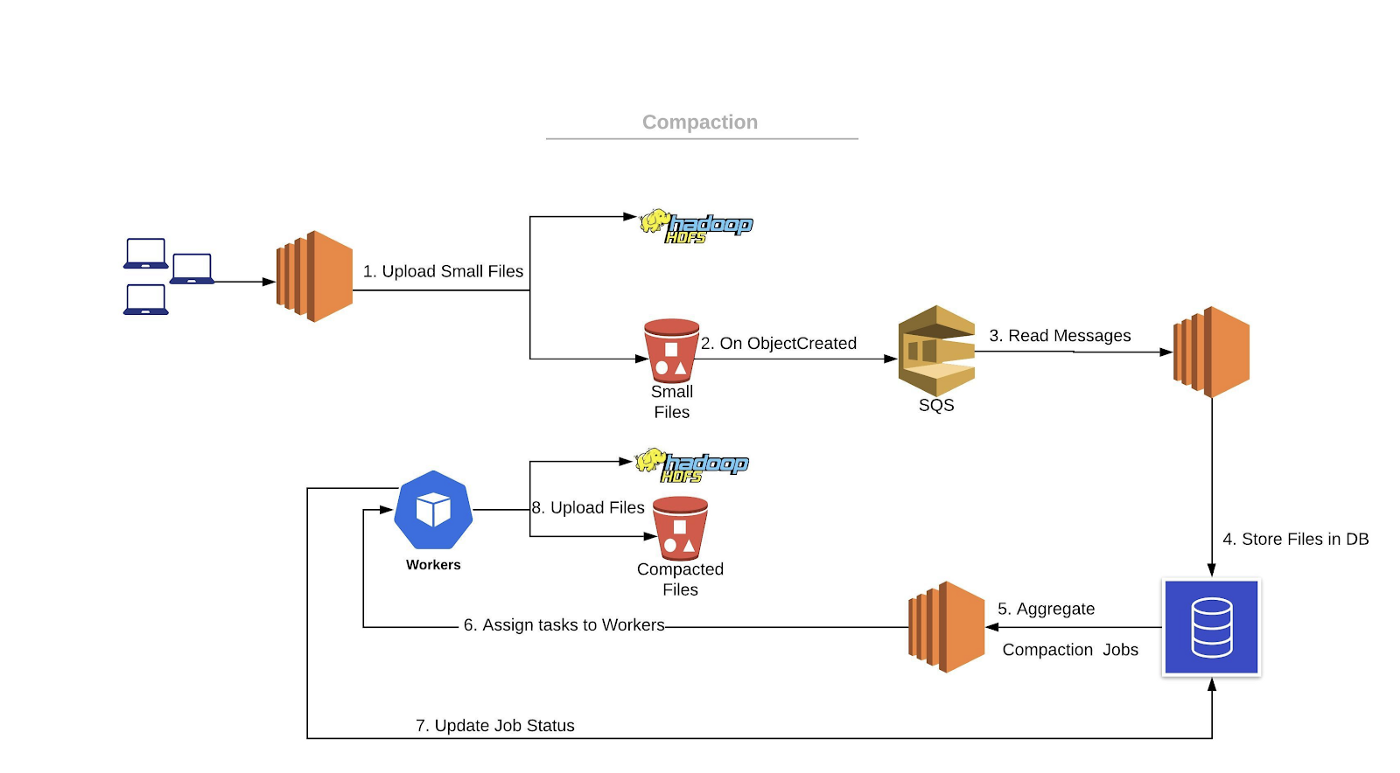
At this point, we decided to take control. We built a custom-made solution for compaction, and we named it Compaction Manager.
- When small files are written to our S3 bucket from our event stream (1), we use AWS event notifications from S3 to SQS on object creation events (2).
- Our service, the Compaction Manager, reads messages from SQS (3) and inserts S3 paths to the database (4).
- Compaction Manager aggregates files ready to be compacted by internal logic (5), and assigns tasks to worker processes (6).
- Workers compact files by internal logic and write big files as output (8).
- The workers update the Compaction Manager on success or failure (7).
What Did We Gain from the Next Generation Solution?
- We control EVERYTHING. We own the logic of compaction, the size of output files and handle retries.
- Our compaction is done continuously, allowing us to have fine-grained control over the amount of workers we trigger. Due to seasonality of the data, resources are utilized effectively, and our worker cluster is autoscaled over time according to the load.
- Our new approach is fault-tolerant. Failure is not a deal breaker any more; the Manager can easily retry the failed batch without restarting the whole process.
- Continuous compaction means that late files are handled as regular files, without special treatment.
- We wrote the entire flow as a continuous compaction process that happens all the time, and thus requires less computation power and is much more robust to failures. We choose the batches of files to compact, so we control memory requirements (as opposed to Presto, where we load all data with a simple select query). We can use Spots instead of On-Demand machines and reduce costs dramatically.
- This approach introduced new opportunities to implement internal logic for compacted files. We choose what files to compact and when. Thus, we can aggregate files by specific criteria, improving queries directly.
Conclusion
We orchestrated our own custom solution to handle huge amounts of data and allow our customers to query it really quickly by utilizing a combination of S3 and HDFS for storage. For first-day data, we enjoy the advantages of HDFS, and for the rest of the data, we rely on S3 because it’s a managed service.
Compaction with Presto is nice, but as we learned it is not enough when you are handling a lot of data. Instead, we solved the challenge with a customised solution which both improved our performance and cut our costs by 80% relative to the original approach.
This post was written by Ariela Shmidt, Big Data SW Engineer and Benny Yashinovsky, Big Data SW Architect at SentinelOne.
If you want to join the team, check out this open position: Big Data Engineer
Like this article? Follow us on LinkedIn, Twitter, YouTube or Facebook to see the content we post.
Read more about Cyber Security
- Email Reply Chain Attacks | What Are They & How Can You Stay Safe?
- 15 macOS Power Tricks for Security Pros
- Is Cryptojacking Going Out Of Fashion or Making A Comeback?
- The Stopwatch Is Ticking | How Ransomware Can Set a Breach Notification In Motion
- The CISO’s Quick Guide to Verizon’s 2020 Data Breach Investigations Report
- 7 Common Ways Ransomware Can Infect Your Organization
- Why On-Device Detection Matters: New Ramsay Trojan Targets Air-Gapped Networks

Leave a Reply
Want to join the discussion?Feel free to contribute!