As recent data confirms, email phishing remains the number one vector for enterprise malware infections, and Business Email Compromise (BEC) the number one cause of financial loss due to internet crime in organizations. While typical phishing and spearphishing attacks attempt to spoof the sender with a forged address, a more sophisticated attack hijacks legitimate email correspondence chains to insert a phishing email into an existing email conversation. The technique, known variously as a ‘reply chain attack’, ‘hijacked email reply chain’ and ‘thread hijack spamming’ was observed by SentinelLabs researchers in their recent analysis of Valak malware. In this post, we dig into how email reply chain attacks work and explain how you can protect yourself and your business from this adversary tactic.

How Do Email Reply Chain Attacks Work?
Hijacking an email reply chain begins with an email account takeover. Either through an earlier compromise and credentials dumping or techniques such as credential stuffing and password-spraying, hackers gain access to one or more email accounts and then begin monitoring conversation threads for opportunities to send malware or poisoned links to one or more of the participants in an ongoing chain of correspondence.
The technique is particularly effective because a bond of trust has already been established between the recipients. The threat actor neither inserts themselves as a new correspondent nor attempts to spoof someone else’s email address. Rather, the attacker sends their malicious email from the genuine account of one of the participants.
Since the attacker has access to the whole thread, they can tailor their malspam message to fit the context of an ongoing conversation. This, on top of the fact that the recipient already trusts the sender, massively increases the chance of the victim opening the malicious attachment or clicking a dangerous link.
To see how this works, suppose an account belonging to “Sam” has been compromised, and the attacker sees that Sam and “Georgie” (and perhaps others) have been discussing a new sales campaign. The attacker can use this context to send Georgie a malicious document that appears related to the conversation they are currently having.
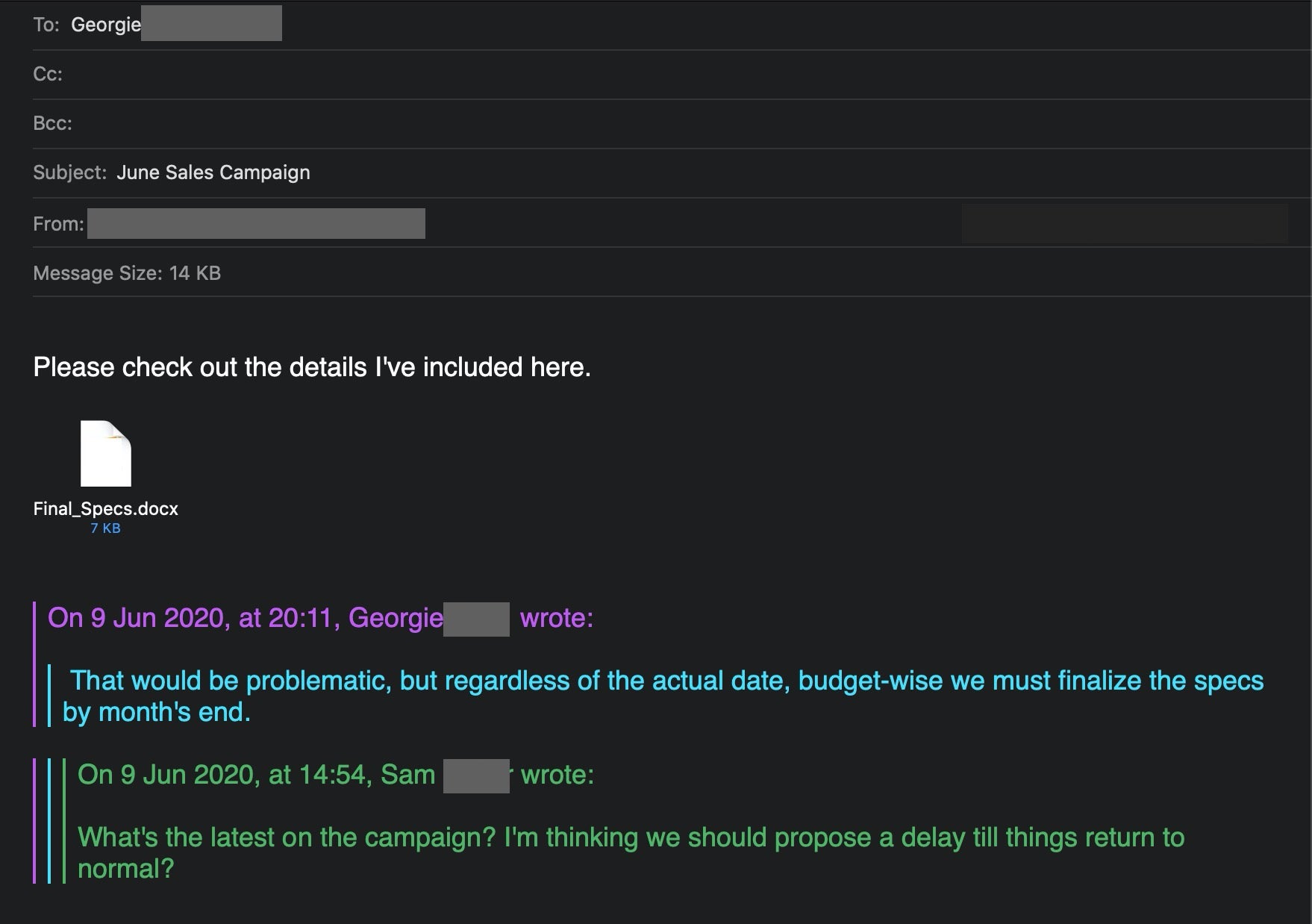
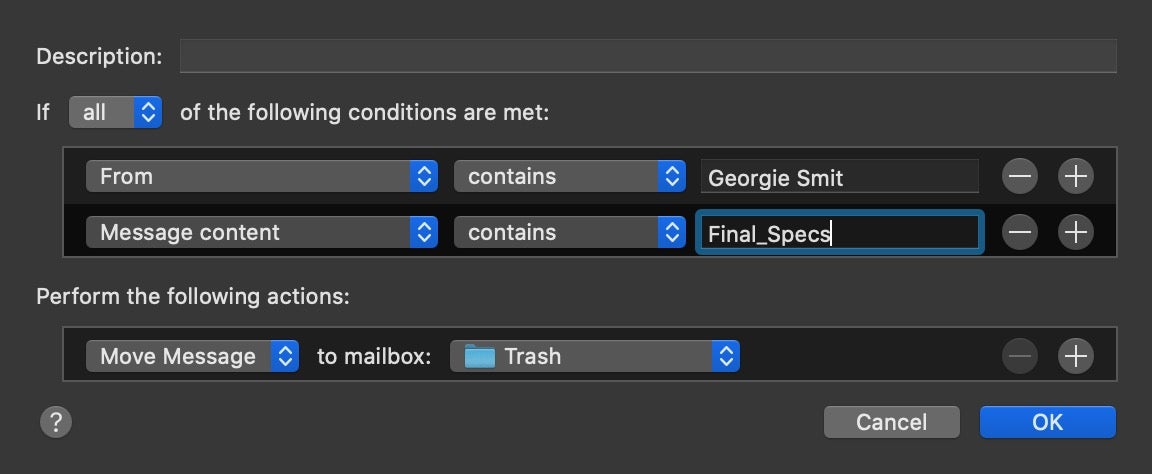
In order to keep the owner of the compromised account ignorant of the attacker’s behaviour, hackers will often use an alternate Inbox to receive messages.
This involves using the email client’s rules to route particular messages away from the usual Inbox and into a folder that the genuine account holder is unlikely to inspect, such as the Trash folder. With this technique, if Georgie in our example replies to Sam’s phishing email, the reply can be diverted so the real Sam never sees it.
Alternatively, when a hacker successfully achieves an account takeover, they may use the email client’s settings to forward mail from certain recipients to another account.
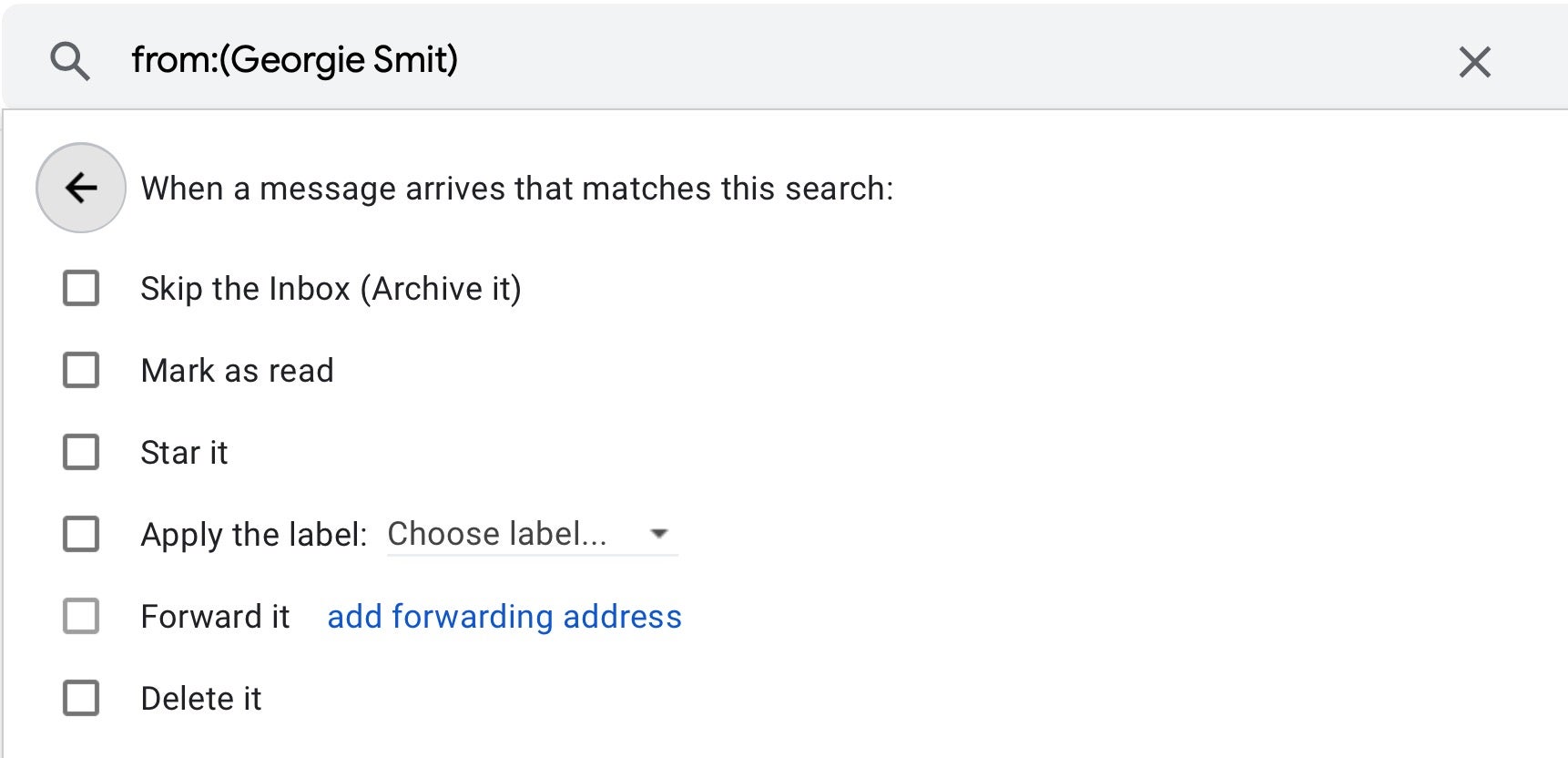
Another trick that can help keep an account holder in the dark is to create an email rule that scans for keywords such as “phish, “phishing, “hack” and “hacked” in incoming messages and deletes them or auto replies to them with a canned message. This prevents any suspicious or concerned colleagues from alerting the account holder with emails like “Have you been hacked?” and so on.
Which Malware Families Have Used Reply Chain Attacks?
Email reply chain attacks began appearing in 2017. In 2018 Gozi ISFB/Ursnif banking trojan campaigns also started using the technique, although in some cases the chain of correspondence itself was faked simply to add legitimacy; in others, the attackers compromised legitimate accounts and used them both to hijack existing threads and to spam other recipients.
Malicious attachments may leverage VBScript and PowerShell through Office Macros to deliver payloads such as Emotet, Ursnif and other loader or banking trojan malware.
SentinelLabs researchers have shown how Valak malware uses specialized plugins designed to steal credentials specifically for use in email reply chain attacks.
As the researchers point out:
“If you are going to leverage reply chain attacks for your spamming campaigns, then you obviously need some email data. It’s interesting to see that when campaigns shifted more towards Valak and away from Gozi, the addition of a plugin surrounding the theft of exchange data showed up.”
Why Are Email Reply Chain Attacks So Effective?
Although spearphishing and even blanket spam phishing campaigns are still a tried-and-trusted method of attack for threat actors, email reply chain attacks raise the bar for defenders considerably.
In ordinary phishing attacks, it is common to see tell-tale grammar and spelling errors, like here.

Also, mass spoofing emails are often sent with subjects or body messages that bear little meaningful context to most recipients, immediately raising suspicion.
Even with more targeted spearphishing attacks, awareness training and safe email practices such as not clicking links, opening attachments from unknown senders or replying to unsolicited emails can have an impact on reducing risk. However, with email reply chain attacks, the usual kind of warning indicators may be missing.
Email reply chain attacks are often carefully-crafted with no language errors, and the leap in credibility gained by inserting a reply to an existing thread from a legitimate sender means that even the most cautious and well-trained staff are at risk of falling victim to this kind of tactic.
How Can You Prevent a Reply Chain Attack?
Given their trusted, legitimate point of origin and the fact that the attacker has email history and conversational context, it can be difficult to spot a well-crafted reply chain attack, particularly if it appears in (or appears to be part of) a long thread with multiple, trusted participants.
However, there are several recommendations that you can follow to avoid becoming a victim of this type of fraud.
First, since reply chain attacks rely on account compromises, ensure that all your enterprise email accounts are following best practices for security. That must include two factor or multi-factor authentication, unique passwords on every account and passwords that are 16 characters in length or longer. Users should be encouraged to regularly inspect their own email client settings and mail rules to make sure that messages are not unknowingly being diverted or deleted.
Second, lock down or entirely forbid use of Office Macros wherever possible. Although these are not the only means by which malicious attachments can compromise a device, Macros remain a common attack vector.
Third, knowledge is power, so expand your user awareness training to include discussion of email reply chain attacks and how they work by referring staff to articles such as this one. Email users need to raise their awareness of how phishing attacks work and how attackers are evolving their techniques. Crucially, they need to understand why it’s important to treat all requests to open attachments or click links with a certain amount of caution, no matter what the source.
Fourth, and most importantly, ensure that your endpoints are protected with a modern, trusted EDR security solution that can stop the execution of malicious code hidden in attachments or links before it does any damage. Legacy AV suites that rely on reputation and YARA rules were not built to handle modern, fileless and polymorphic attacks. A next-gen, automated AI-powered platform is the bare minimum in today’s cyber security threatscape.
Conclusion
Email reply chain attacks are yet another form of social engineering deployed by threat actors to achieve their aims. Unlike the physical world with its hardcoded laws of nature, there are no rules in the cyber world that cannot be changed either by manipulating the hardware, the software or the user. This, however, is just as true for defenders as it is for attackers. By keeping control of all aspects of our cyber environment, we can defeat attacks before they occur or create lasting damage to the organization. Secure your devices, educate your users, train your staff, and let the criminals find another target.
Like this article? Follow us on LinkedIn, Twitter, YouTube or Facebook to see the content we post.
Read more about Cyber Security