You hear so much about data these days that you might forget that a huge amount of the world runs on documents: a veritable menagerie of heterogeneous files and formats holding enormous value yet incompatible with the new era of clean, structured databases. Docugami plans to change that with a system that intuitively understands any set of documents and intelligently indexes their contents — and NASA is already on board.
If Docugami’s product works as planned, anyone will be able to take piles of documents accumulated over the years and near-instantly convert them to the kind of data that’s actually useful to people.
If Docugami’s product works as planned, anyone will be able to take piles of documents accumulated over the years and near-instantly convert them to the kind of data that’s actually useful to people.
Because it turns out that running just about any business ends up producing a ton of documents. Contracts and briefs in legal work, leases and agreements in real estate, proposals and releases in marketing, medical charts, etc, etc. Not to mention the various formats: Word docs, PDFs, scans of paper printouts of PDFs exported from Word docs, and so on.
Over the last decade there’s been an effort to corral this problem, but movement has largely been on the organizational side: put all your documents in one place, share and edit them collaboratively. Understanding the document itself has pretty much been left to the people who handle them, and for good reason — understanding documents is hard!
Think of a rental contract. We humans understand when the renter is named as Jill Jackson, that later on, “the renter” also refers to that person. Furthermore, in any of a hundred other contracts, we understand that the renters in those documents are the same type of person or concept in the context of the document, but not the same actual person. These are surprisingly difficult concepts for machine learning and natural language understanding systems to grasp and apply. Yet if they could be mastered, an enormous amount of useful information could be extracted from the millions of documents squirreled away around the world.
What’s up, .docx?
Docugami founder Jean Paoli says they’ve cracked the problem wide open, and while it’s a major claim, he’s one of few people who could credibly make it. Paoli was a major figure at Microsoft for decades, and among other things helped create the XML format — you know all those files that end in x, like .docx and .xlsx? Paoli is at least partly to thank for them.
“Data and documents aren’t the same thing,” he told me. “There’s a thing you understand, called documents, and there’s something that computers understand, called data. Why are they not the same thing? So my first job [at Microsoft] was to create a format that can represent documents as data. I created XML with friends in the industry, and Bill accepted it.” (Yes, that Bill.)
The formats became ubiquitous, yet 20 years later the same problem persists, having grown in scale with the digitization of industry after industry. But for Paoli the solution is the same. At the core of XML was the idea that a document should be structured almost like a webpage: boxes within boxes, each clearly defined by metadata — a hierarchical model more easily understood by computers.
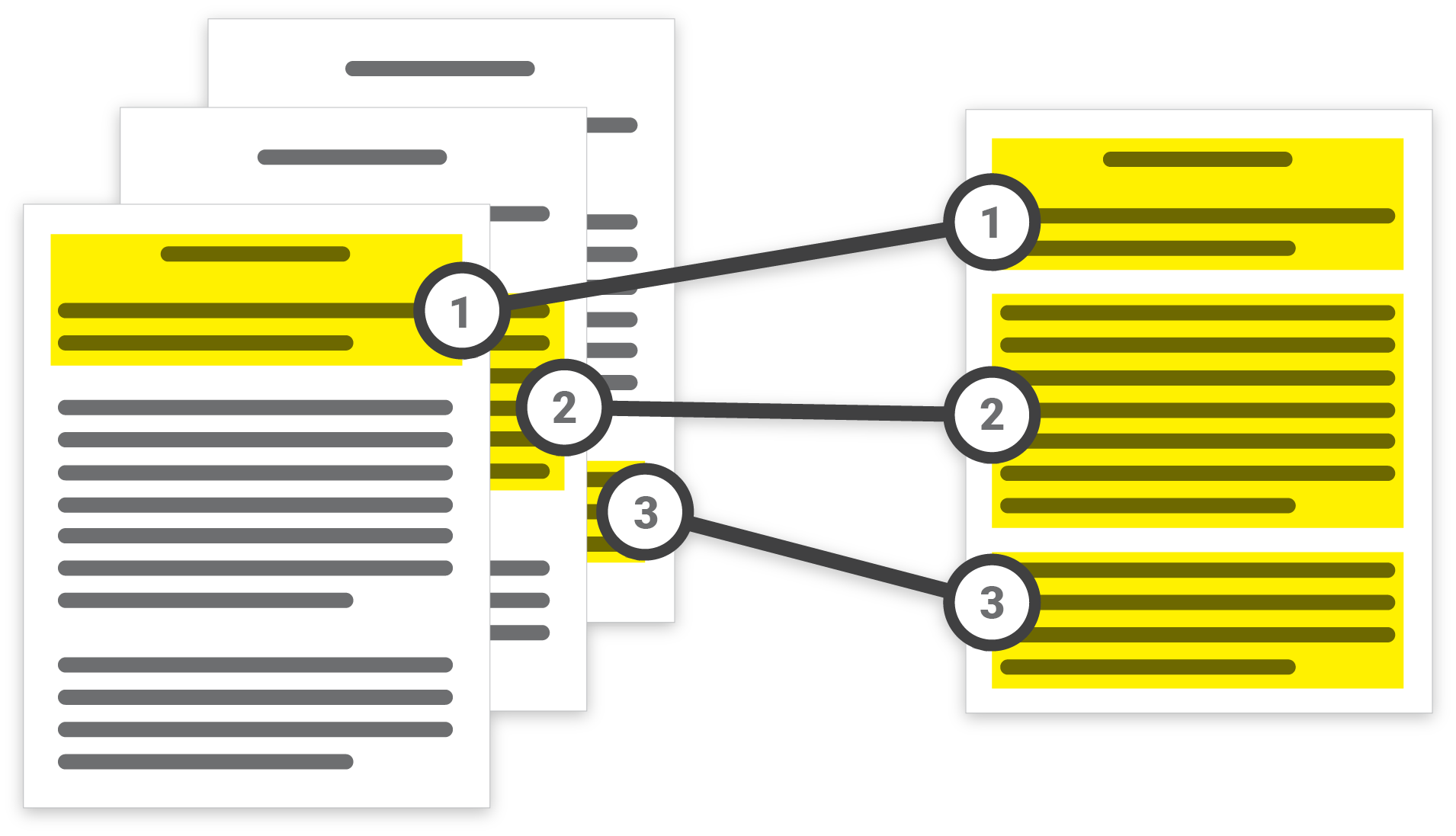
Image Credits: Docugami
“A few years ago I drank the AI kool-aid, got the idea to transform documents into data. I needed an algorithm that navigates the hierarchical model, and they told me that the algorithm you want does not exist,” he explained. “The XML model, where every piece is inside another, and each has a different name to represent the data it contains — that has not been married to the AI model we have today. That’s just a fact. I hoped the AI people would go and jump on it, but it didn’t happen.” (“I was busy doing something else,” he added, to excuse himself.)
The lack of compatibility with this new model of computing shouldn’t come as a surprise — every emerging technology carries with it certain assumptions and limitations, and AI has focused on a few other, equally crucial areas like speech understanding and computer vision. The approach taken there doesn’t match the needs of systematically understanding a document.
“Many people think that documents are like cats. You train the AI to look for their eyes, for their tails … documents are not like cats,” he said.
It sounds obvious, but it’s a real limitation. Advanced AI methods like segmentation, scene understanding, multimodal context, and such are all a sort of hyperadvanced cat detection that has moved beyond cats to detect dogs, car types, facial expressions, locations, etc. Documents are too different from one another, or in other ways too similar, for these approaches to do much more than roughly categorize them.
As for language understanding, it’s good in some ways but not in the ways Paoli needed. “They’re working sort of at the English language level,” he said. “They look at the text but they disconnect it from the document where they found it. I love NLP people, half my team is NLP people — but NLP people don’t think about business processes. You need to mix them with XML people, people who understand computer vision, then you start looking at the document at a different level.”
Docugami in action

Image Credits: Docugami
Paoli’s goal couldn’t be reached by adapting existing tools (beyond mature primitives like optical character recognition), so he assembled his own private AI lab, where a multidisciplinary team has been tinkering away for about two years.
“We did core science, self-funded, in stealth mode, and we sent a bunch of patents to the patent office,” he said. “Then we went to see the VCs, and SignalFire basically volunteered to lead the seed round at $10 million.”
Coverage of the round didn’t really get into the actual experience of using Docugami, but Paoli walked me through the platform with some live documents. I wasn’t given access myself and the company wouldn’t provide screenshots or video, saying it is still working on the integrations and UI, so you’ll have to use your imagination … but if you picture pretty much any enterprise SaaS service, you’re 90% of the way there.
As the user, you upload any number of documents to Docugami, from a couple dozen to hundreds or thousands. These enter a machine understanding workflow that parses the documents, whether they’re scanned PDFs, Word files, or something else, into an XML-esque hierarchical organization unique to the contents.
“Say you’ve got 500 documents, we try to categorize it in document sets, these 30 look the same, those 20 look the same, those five together. We group them with a mix of hints coming from how the document looked, what it’s talking about, what we think people are using it for, etc.,” said Paoli. Other services might be able to tell the difference between a lease and an NDA, but documents are too diverse to slot into pre-trained ideas of categories and expect it to work out. Every set of documents is potentially unique, and so Docugami trains itself anew every time, even for a set of one. “Once we group them, we understand the overall structure and hierarchy of that particular set of documents, because that’s how documents become useful: together.”
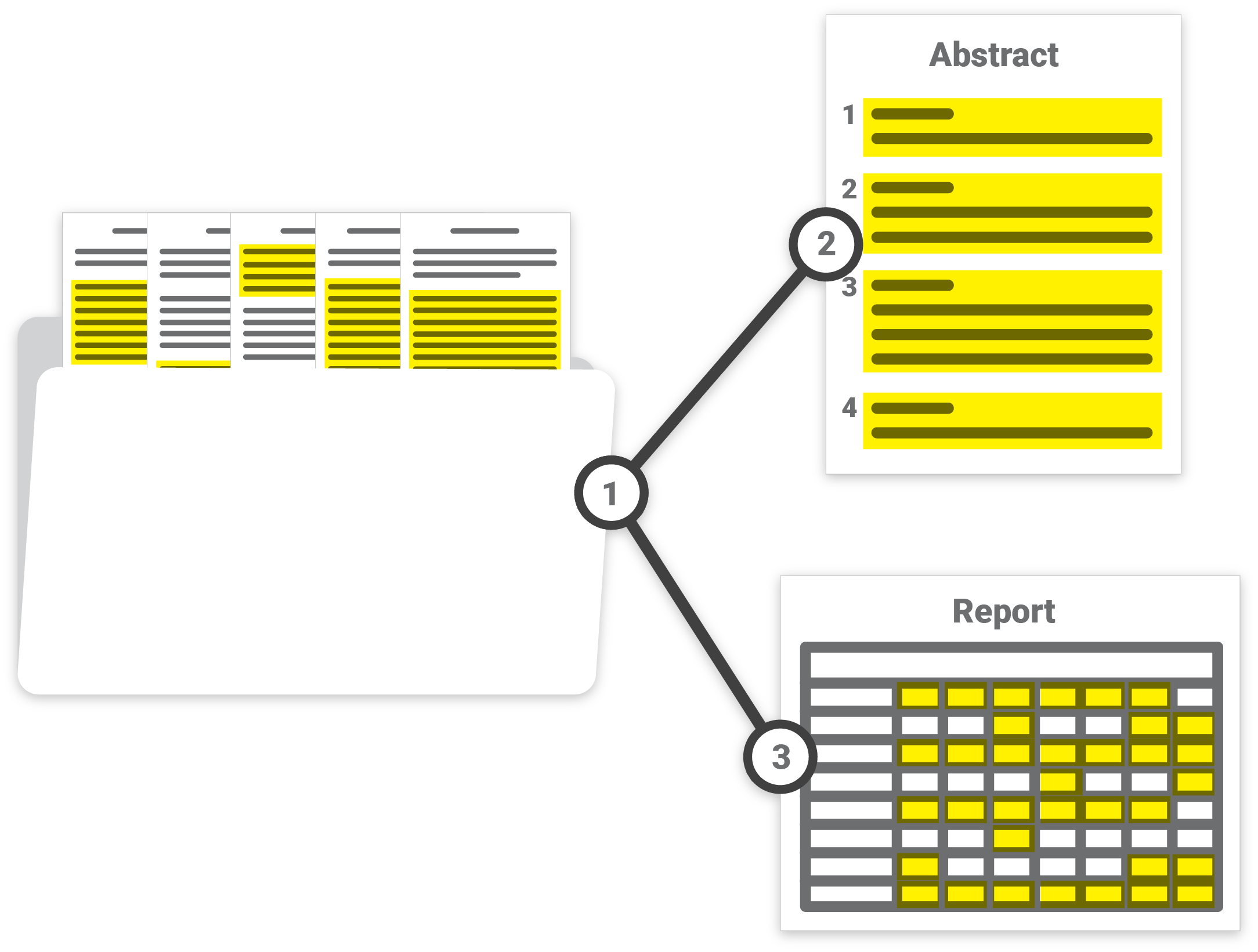
Image Credits: Docugami
That doesn’t just mean it picks up on header text and creates an index, or lets you search for words. The data that is in the document, for example who is paying whom, how much and when, and under what conditions, all that becomes structured and editable within the context of similar documents. (It asks for a little input to double check what it has deduced.)
It can be a little hard to picture, but now just imagine that you want to put together a report on your company’s active loans. All you need to do is highlight the information that’s important to you in an example document — literally, you just click “Jane Roe” and “$20,000” and “five years” anywhere they occur — and then select the other documents you want to pull corresponding information from. A few seconds later you have an ordered spreadsheet with names, amounts, dates, anything you wanted out of that set of documents.
All this data is meant to be portable too, of course — there are integrations planned with various other common pipes and services in business, allowing for automatic reports, alerts if certain conditions are reached, automated creation of templates and standard documents (no more keeping an old one around with underscores where the principals go).
Remember, this is all half an hour after you uploaded them in the first place, no labeling or pre-processing or cleaning required. And the AI isn’t working from some preconceived notion or format of what a lease document looks like. It’s learned all it needs to know from the actual docs you uploaded — how they’re structured, where things like names and dates figure relative to one another, and so on. And it works across verticals and uses an interface anyone can figure out in a few minutes. Whether you’re in healthcare data entry or construction contract management, the tool should make sense.
The web interface where you ingest and create new documents is one of the main tools, while the other lives inside Word. There Docugami acts as a sort of assistant that’s fully aware of every other document of whatever type you’re in, so you can create new ones, fill in standard information, comply with regulations and so on.
Okay, so processing legal documents isn’t exactly the most exciting application of machine learning in the world. But I wouldn’t be writing this (at all, let alone at this length) if I didn’t think this was a big deal. This sort of deep understanding of document types can be found here and there among established industries with standard document types (such as police or medical reports), but have fun waiting until someone trains a bespoke model for your kayak rental service. But small businesses have just as much value locked up in documents as large enterprises — and they can’t afford to hire a team of data scientists. And even the big organizations can’t do it all manually.
NASA’s treasure trove

Image Credits: NASA
The problem is extremely difficult, yet to humans seems almost trivial. You or I could glance through 20 similar documents and a list of names and amounts easily, perhaps even in less time than it takes for Docugami to crawl them and train itself.
But AI, after all, is meant to imitate and transcend human capacity, and it’s one thing for an account manager to do monthly reports on 20 contracts — quite another to do a daily report on a thousand. Yet Docugami accomplishes the latter and former equally easily — which is where it fits into both the enterprise system, where scaling this kind of operation is crucial, and to NASA, which is buried under a backlog of documentation from which it hopes to glean clean data and insights.
If there’s one thing NASA’s got a lot of, it’s documents. Its reasonably well-maintained archives go back to its founding, and many important ones are available by various means — I’ve spent many a pleasant hour perusing its cache of historical documents.
But NASA isn’t looking for new insights into Apollo 11. Through its many past and present programs, solicitations, grant programs, budgets, and of course engineering projects, it generates a huge amount of documents — being, after all, very much a part of the federal bureaucracy. And as with any large organization with its paperwork spread over decades, NASA’s document stash represents untapped potential.
Expert opinions, research precursors, engineering solutions, and a dozen more categories of important information are sitting in files searchable perhaps by basic word matching but otherwise unstructured. Wouldn’t it be nice for someone at JPL to get it in their head to look at the evolution of nozzle design, and within a few minutes have a complete and current list of documents on that topic, organized by type, date, author and status? What about the patent advisor who needs to provide a NIAC grant recipient information on prior art — shouldn’t they be able to pull those old patents and applications up with more specificity than any with a given keyword?
The NASA SBIR grant, awarded last summer, isn’t for any specific work, like collecting all the documents of such and such a type from Johnson Space Center or something. It’s an exploratory or investigative agreement, as many of these grants are, and Docugami is working with NASA scientists on the best ways to apply the technology to their archives. (One of the best applications may be to the SBIR and other small business funding programs themselves.)
Another SBIR grant with the NSF differs in that, while at NASA the team is looking into better organizing tons of disparate types of documents with some overlapping information, at NSF they’re aiming to better identify “small data.” “We are looking at the tiny things, the tiny details,” said Paoli. “For instance, if you have a name, is it the lender or the borrower? The doctor or the patient name? When you read a patient record, penicillin is mentioned, is it prescribed or prohibited? If there’s a section called allergies and another called prescriptions, we can make that connection.”
“Maybe it’s because I’m French”
When I pointed out the rather small budgets involved with SBIR grants and how his company couldn’t possibly survive on these, he laughed.
“Oh, we’re not running on grants! This isn’t our business. For me, this is a way to work with scientists, with the best labs in the world,” he said, while noting many more grant projects were in the offing. “Science for me is a fuel. The business model is very simple — a service that you subscribe to, like Docusign or Dropbox.”
The company is only just now beginning its real business operations, having made a few connections with integration partners and testers. But over the next year it will expand its private beta and eventually open it up — though there’s no timeline on that just yet.
“We’re very young. A year ago we were like five, six people, now we went and got this $10 million seed round and boom,” said Paoli. But he’s certain that this is a business that will be not just lucrative but will represent an important change in how companies work.
“People love documents. Maybe it’s because I’m French,” he said, “but I think text and books and writing are critical — that’s just how humans work. We really think people can help machines think better, and machines can help people think better.”