The Good, the Bad and the Ugly in Cybersecurity – Week 17
The Good | U.S. Govt Sends Spyware Abusers, Cybercriminals, and Crypto Launderers to Court
The U.S. government this week took three decisive actions against cyber criminals: a visa ban on thirteen spyware makers and sellers, sanctions against four Iranian nationals for their roles in recent cyberattacks, and an official charge for two cryptomixers.
Following the February announcement to set visa restrictions on commercial spyware developers and vendors, the Department of State has cracked down on the first thirteen individuals and their families. Excluding visa applications in this case effectively bans those who are linked to such operations from entering the U.S. The abuse of spyware has been a rising issue in recent years as adversaries use it to target persons of interest such as journalists, human rights advocates, academics, and government employees.
Two front companies and four individuals were sanctioned by the U.S. Treasury Department’s Office of Foreign Assets Control (OFAC) for their association to cyber activities supporting the Iranian Islamic Revolutionary Guard Corps Cyber Electronic Command (IRGC-CEC) over the span of five years. Collectively, the identified threat actors have targeted over a dozen U.S. organizations, including the U.S. government and defense contractors through spear phishing and malware attacks, compromising over 200,000 employee accounts.
Up to $10 Million Reward & Possible Relocation
These individuals conducted malicious cyber ops against U.S. firms and government agencies on behalf of Iran’s IRGC.
If you have info on them, contact us. Your tip could be worth millions of $ and a plane ticket to somewhere new. pic.twitter.com/EjOGLXDeJl
— Rewards for Justice (@RFJ_USA) April 23, 2024
Responsible for processing more than $2 billion in ill-got funds for various criminal enterprises over nine years, two individuals have been charged by the Department of Justice for money laundering and operating an unlicensed money-transmitting business. Their services ‘Samourai’ and ‘Ricochet’ allowed criminals to sidestep law enforcement and hinder crypto exchanges from tracking the illegal source of the funds. Such services often provide a haven for criminals who require large-scale laundering efforts and evasion from sanctions.
The Bad | Nation-State Actors Breach MITRE Research Center via Ivanti Zero-Days
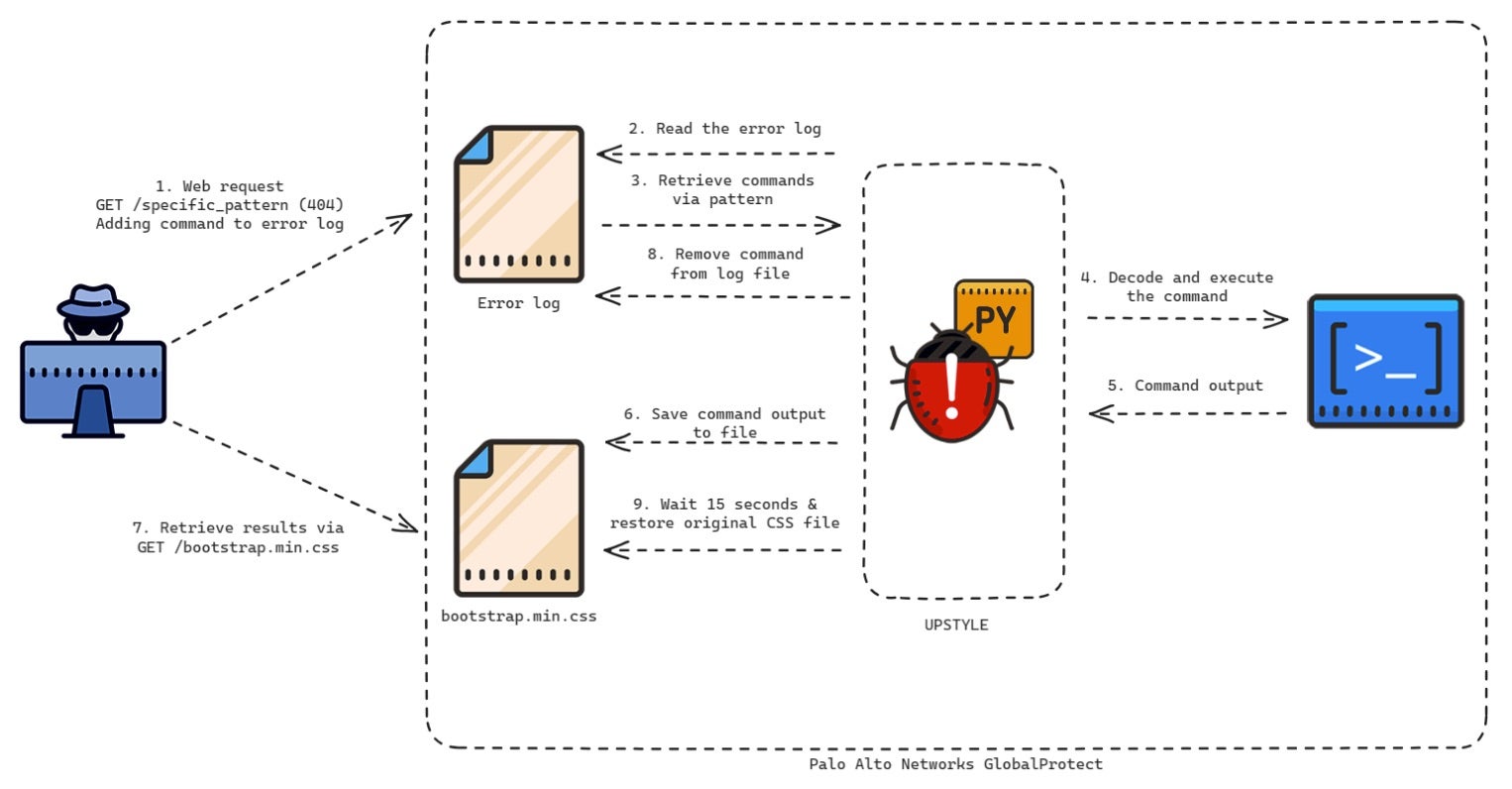
MITRE Corporation disclosed a breach of their systems this week after threat actors chained two Ivanti zero-day vulnerabilities together in the attack. The breach was discovered in January when suspicious activity was found on MITRE’s unclassified prototyping network, Network Experimentation Research and Virtualization Environment (NERVE). MITRE’s research and development centers employ the nation’s leading scientists and engineers, building digital solutions for military, security, and intelligence organizations across the U.S.
After containing the incident, MITRE stated that affected parties were properly informed and relevant authorities engaged, with current efforts focused on restoring operations. Ongoing investigations show that the core network and partner systems were unaffected by the intrusion.
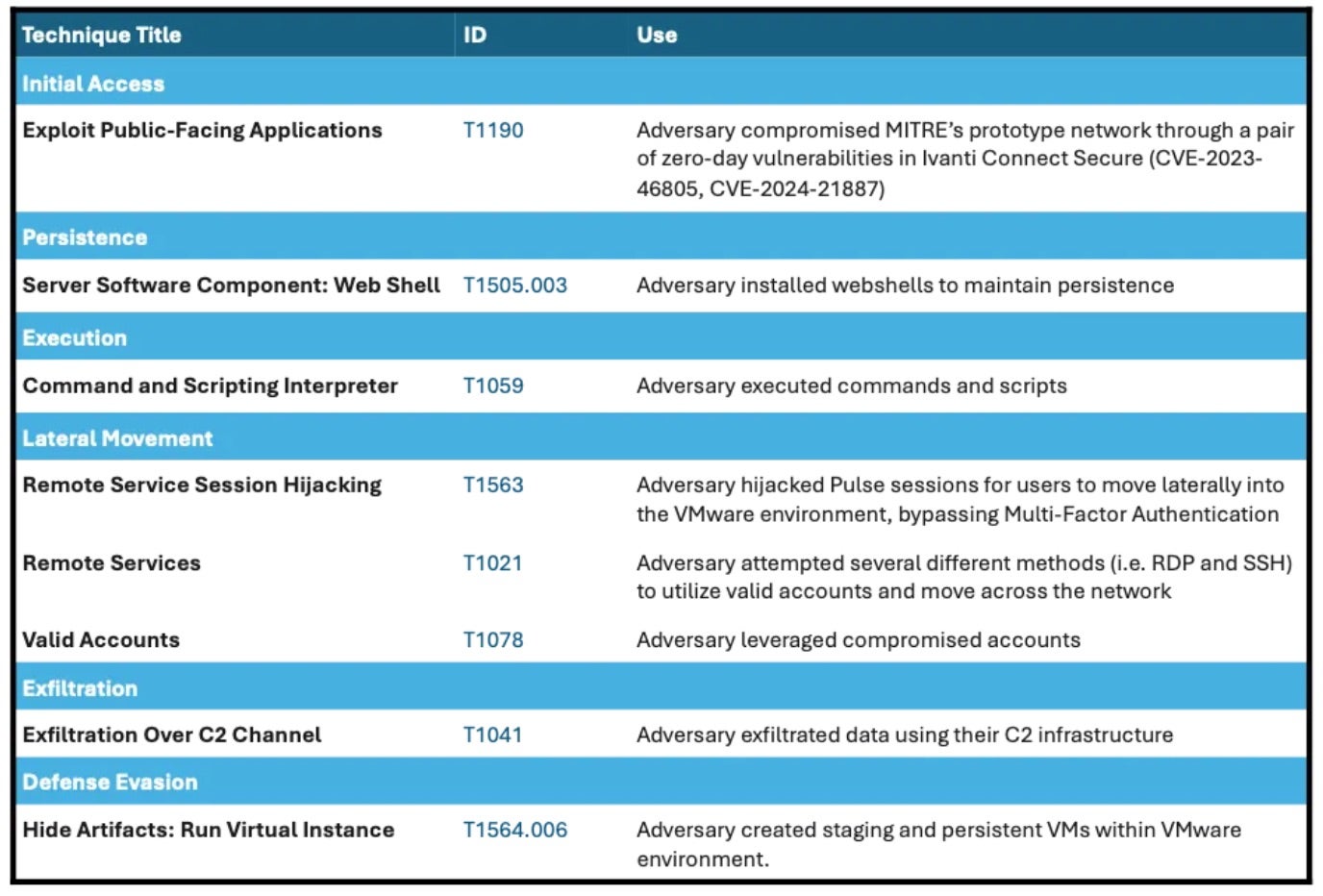
The threat actors compromised the non-profit’s VPNs by exploiting two Ivanti Connect Secure zero-days: an authentication bypass flaw tracked as CVE-2023-46805 (CVSS 8.2) and CVE-2024-21887 (CVSS 9.1), a command injection flaw. Together, they allowed the attacker to use session hijacking to bypass multi-factor authentication (MFA) measures and move laterally through the network’s VMware infrastructure with an administrative account. Forensics also show the actors employing a combination of webshells and backdoors to establish persistence and harvest credentials.
The breach is suspected to be the work of state-sponsored threat actors and serves as a striking reminder that even cutting edge and highly-funded organizations are not immune from cyber threats. Targets on the level of NERVE, which in this case houses invaluable information on experimental methodologies and technologies, continue to be extremely lucrative for nation-state adversaries looking to either potentially steal or sabotage sensitive resources.
MITRE has released tactics, techniques, and procedures (TTPs) related to the breach in effort to spread lessons learned within the infosec community. CISA has also shared technical details and IoCs in a recent advisory.
The Ugly | GRU-Based APT Exploits Old Windows Flaw with New GooseEgg Tool to Target Government Entities
Despite being patched back in October 2022, a Windows Print Spooler vulnerability tracked as CVE-2022-38028 (CVSS 7.8) has made its way back into headlines this week. This time weaponized by GRU-linked threat group APT28 (aka Forest Blizzard or Strontium), the flaw delivers a previously unknown custom malware dubbed ‘GooseEgg’ to perform a slew of post-compromise activities.
GooseEgg has been leveraged possibly as early as April 2019 and has now been observed in attacks targeting North American, Western European, and Ukrainian governments, non-profit organizations, educational institutions, and transportation entities.
Typically, GooseEgg is deployed with a batch script named either execute.bat and doit.bat, which triggers the executable and sets up persistence in the form of a scheduled task designed to run servtask.bat. The malware tool works by enabling the deployment of a malicious DLL (usually containing wayzgoose) capable of spawning other applications with SYSTEM-level permissions that allow attackers to perform remote code execution (RCE), backdoor installations, and lateral movement.

APT28 is often known to use publicly available exploits alongside this Windows Print Spooler flaw, including CVE-2023-23397 and the PrintNightmare vulnerabilities tracked as CVE-2021-34527 and CVE-2021-1675. Researchers note that APT28 deploys GooseEgg to enable checking exploit success, customer version identification, and privilege escalation – all in support of their main objective to steal credentials and maintain access on the compromised target.
Advanced and well-resourced threat groups like APT28 continually refine their approach, testing new and custom malware and techniques to avoid attribution. CISA has since added CVE-2022-38028 to its KEV catalog and urged federal agencies to identify any systems vulnerable to the flaw and apply the available patch.





 Cyber Army of Russia claims to be targeting US water facilities
Cyber Army of Russia claims to be targeting US water facilities