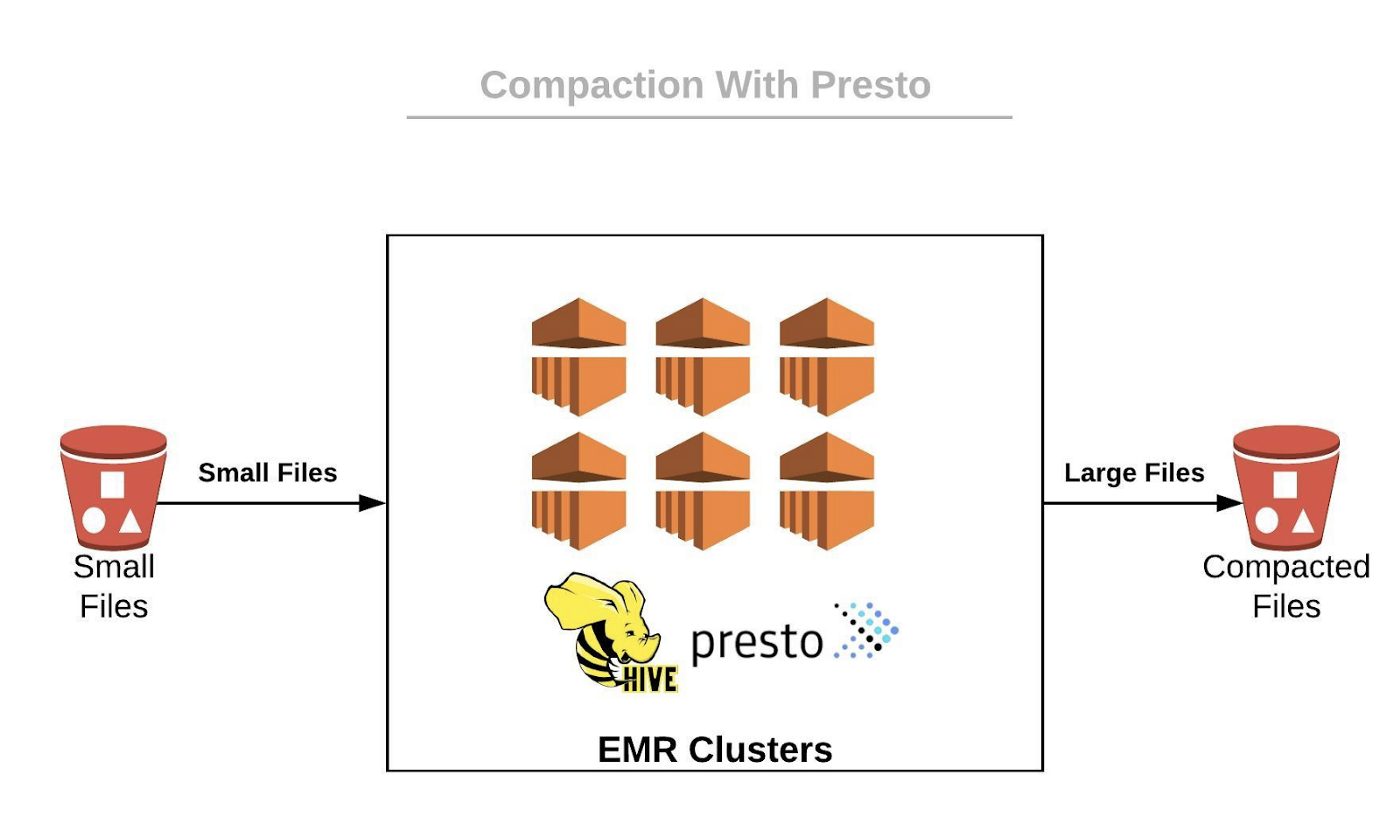
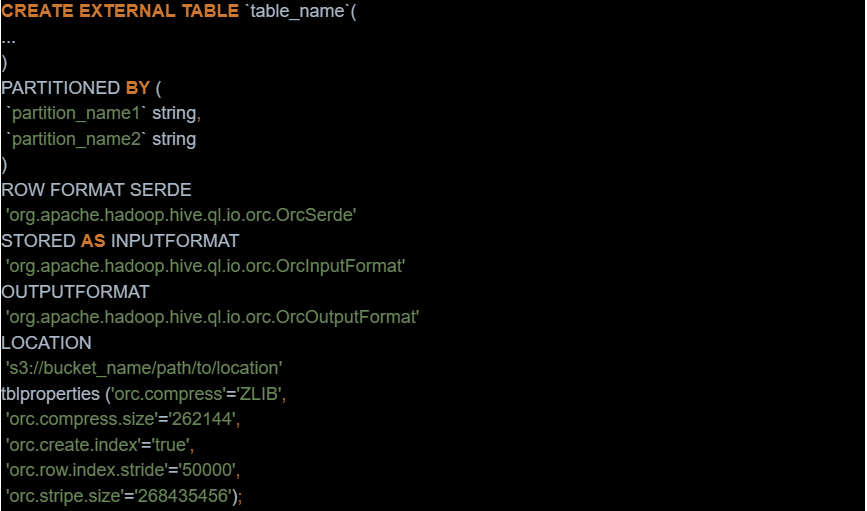
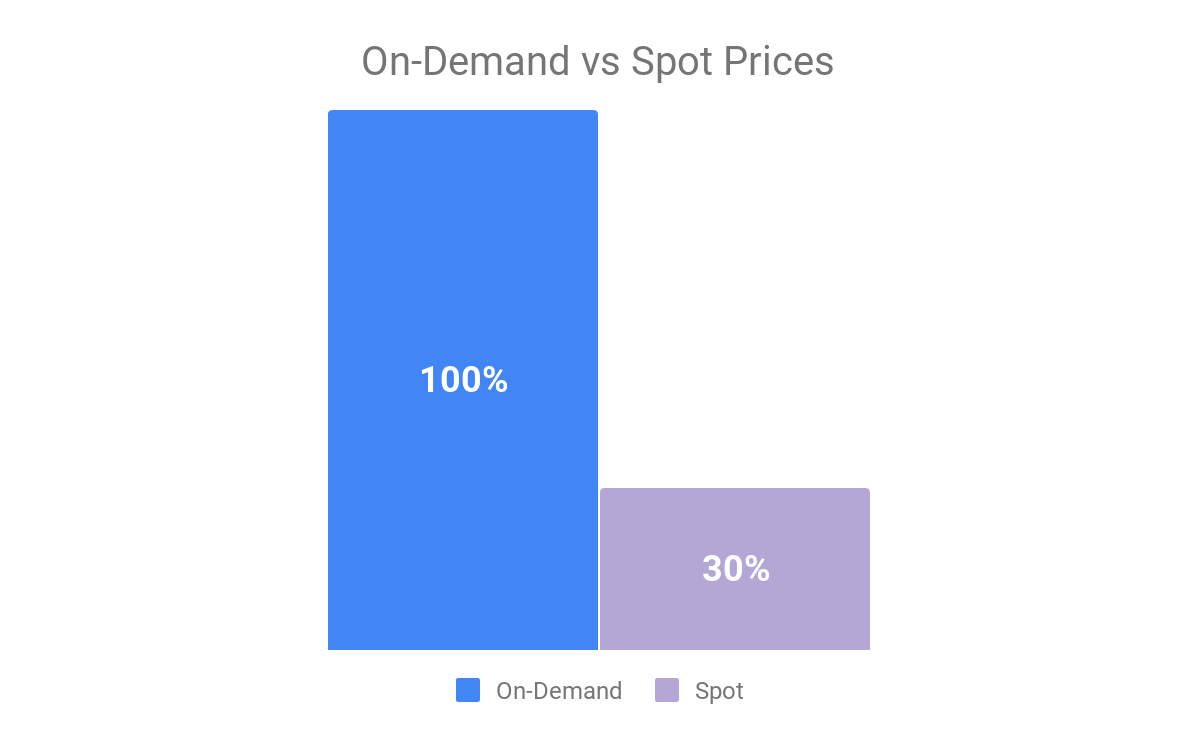
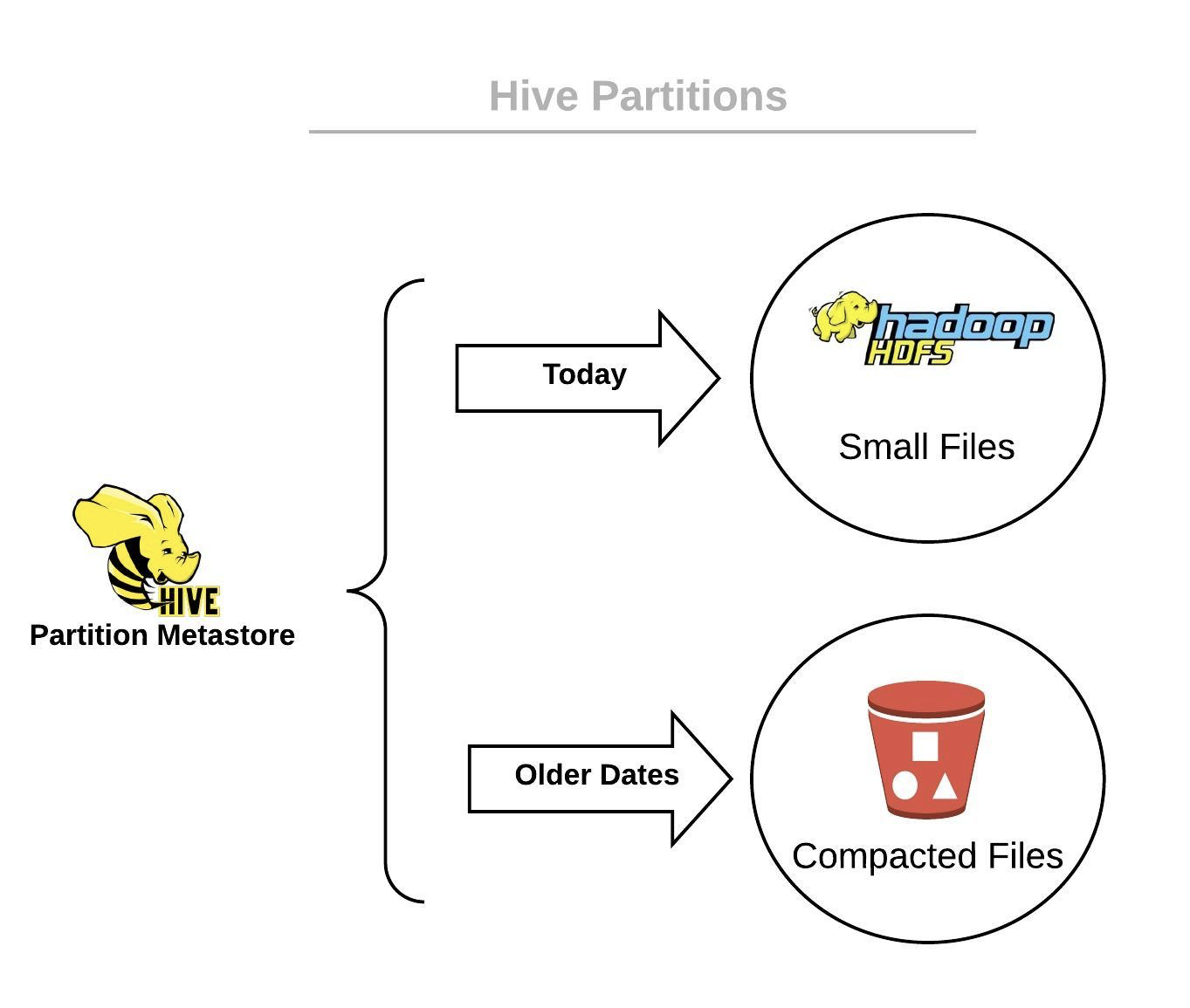
VESoft raises $8M to meet China’s growing need for graph databases
Sherman Ye founded VESoft in 2018 when he saw a growing demand for graph databases in China. Its predecessors, like Neo4j and TigerGraph, had already been growing aggressively in the West for a few years, while China was just getting to know the technology that leverages graph structures to store data sets and depict their relationships, such as those used for social media analysis, e-commerce recommendations and financial risk management.
VESoft is ready for further growth after closing an $8 million funding round led by Redpoint China Ventures, an investment firm launched by Silicon Valley-based Redpoint Ventures in 2005. Existing investor Matrix Partners China also participated in the Series pre-A round. The new capital will allow the startup to develop products and expand to markets in North America, Europe and other parts of Asia.
The 30-people team is comprised of former employees from Alibaba, Facebook, Huawei and IBM. It’s based in Hangzhou, a scenic city known for its rich history and housing Alibaba and its financial affiliate Ant Financial, where Ye previously worked as a senior engineer after his four-year stint with Facebook in California. From 2017 to 2018, the entrepreneur noticed that Ant Financial’s customers were increasingly interested in adopting graph databases as an alternative to relational databases, a model that had been popular since the 80s and normally organizes data into tables.
“While relational databases are capable of achieving many functions carried out by graph databases… they deteriorate in performance as the quantity of data grows,” Ye told TechCrunch during an interview. “We didn’t use to have so much data.”
Information explosion is one reason why Chinese companies are turning to graph databases, which can handle millions of transactions to discover patterns within scattered data. The technology’s rise is also a response to new forms of online businesses that depend more on relationships.
“Take recommendations for example. The old model recommends content based purely on user profiles, but the problem of relying on personal browsing history is it fails to recommend new things. That was fine for a long time as the Chinese [internet] market was big enough to accommodate many players. But as the industry becomes saturated and crowded… companies need to ponder how to retain existing users, lengthen their time spent, and win users from rivals.”
The key lies in serving people content and products they find appealing. Graph databases come in handy, suggested Ye, when services try to predict users’ interest or behavior as the model uncovers what their friends or people within their social circles like. “That’s a lot more effective than feeding them what’s trending.”
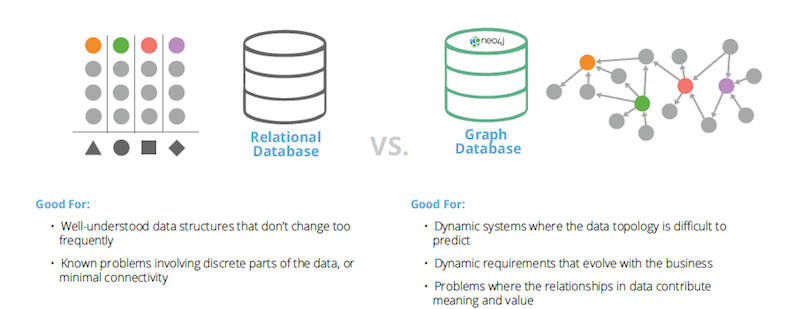
Neo4j compares relational and graph databases (Link)
The company has made its software open source, which the founder believed can help cultivate a community of graph database users and educate the market in China. It will also allow VESoft to reach more engineers in the English-speaking world who are well-acquainted with the open-source culture.
“There is no such thing as being ‘international’ or ‘domestic’ for a technology-driven company. There are no boundaries between countries in the open-source world,” reckoned Ye.
When it comes to generating income, the startup plans to launch a paid version for enterprises, which will come with customized plug-ins and host services.
The Nebula Graph, the brand of VESoft’s database product, is now serving 20 enterprise clients from areas across social media, e-commerce and finance, including big names like food delivery giant Meituan, popular social commerce app Xiaohongshu and e-commerce leader JD.com. A number of overseas companies are also trialing Nebula.
The time is ripe for enterprise-facing startups with a technological moat in China as the market for consumers has been divided by incumbents like Tencent and Alibaba. This makes fundraising relatively easy for VESoft. The founder is confident that Chinese companies are rapidly catching up with their Western counterparts in the space, for the gargantuan amount of data and the myriad of ways data is used in the country “will propel the technology forward.”
![]()